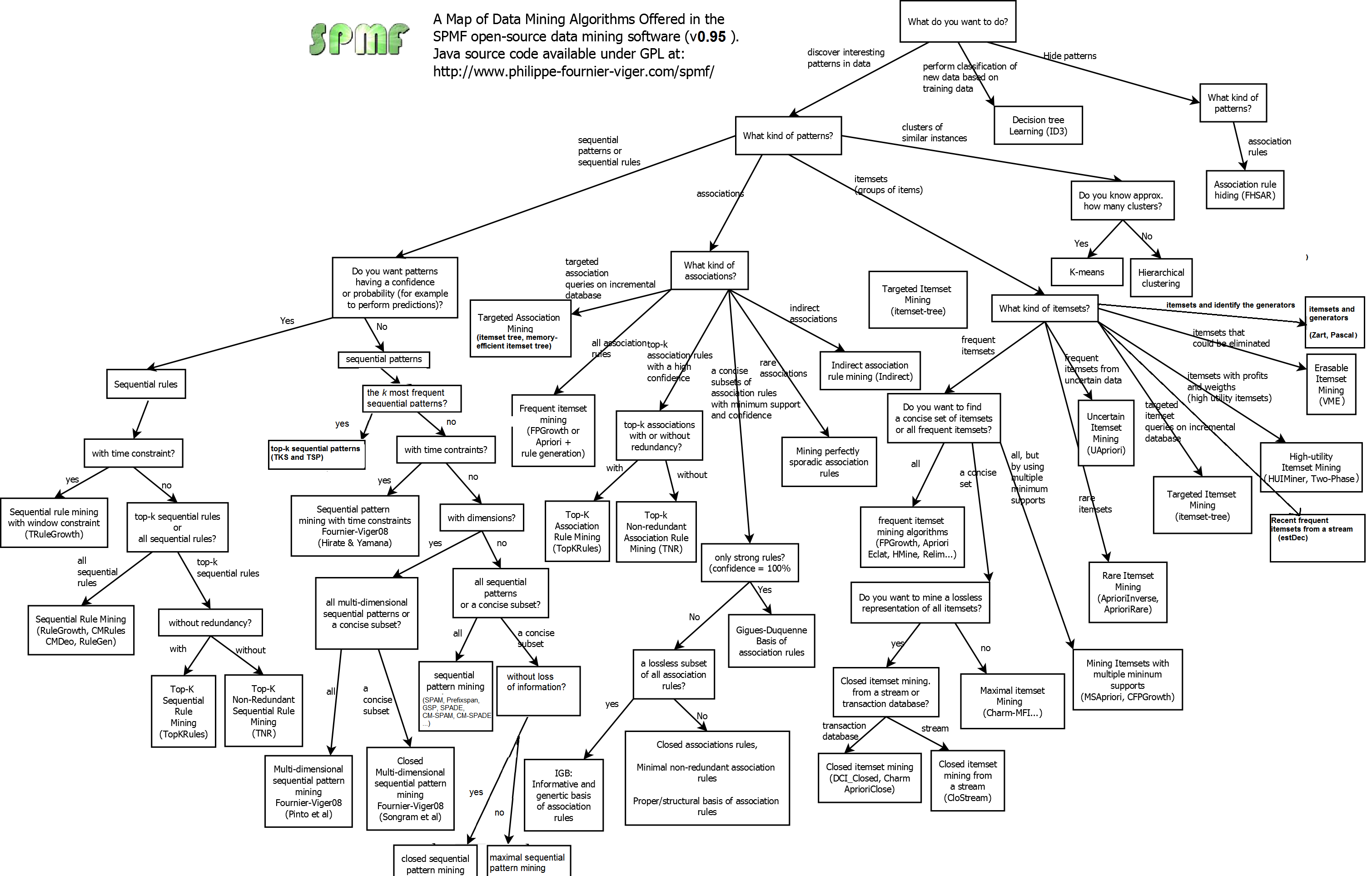
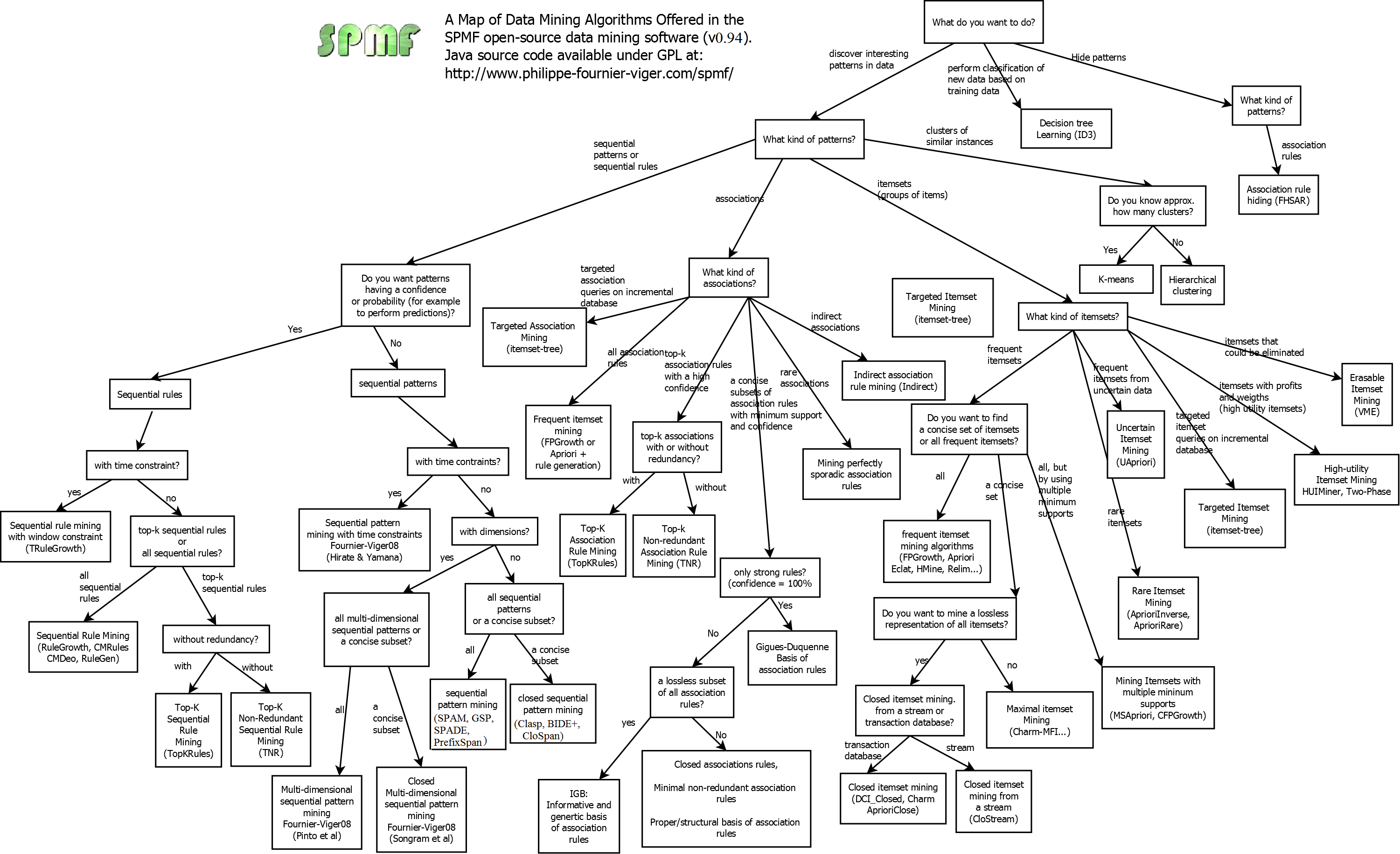
There are two versions of SPMF:
| Source code version (262 algorithms) | Release version (238 algorithms) |
|
1) Download spmf.zip 2) Read the instructions for installing and running the source code: how_to compile source code and run it 3) After you have installed the source code, if you intend to modify the source code and/or reuse it in other Java projects, you may want to read the developer's guide, which provides information about the source code organization. Algorithms included: all the algorithms |
1) Download spmf.jar and the sample data files test_files.zip 2) If you want to use the graphical interface, follow these instructions: how_to_run_the graphical_interface If you want to use the command line interface, follow these
instructions: Algorithms included: all except CloStream,
estDec, estDec+, ItemsetTree, Memory-Efficient Itemset Tree,
ID3, and a few others |
If you have any questions, you may first have a look at the FAQ, and then ask your question in the data mining forum. If the question has to be private, you can send-me an e-mail.
If you want to use SPMF from programs written in other languages such as Python and R, you may call SPMF from the command line or use some unofficial wrappers for SPMF. A limitations of wrappers is that they may not support all algorithms from SPMF.
Release notes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}