Mining Multiple Fuzzy Frequent Itemsets in a quantitatve transaction database using the MFFI-Miner algorithm (SPMF documentation)
This example explains how to run the MFFI-Miner algorithm using the SPMF open-source data mining library.
How to run this example?
- If you are using the graphical interface, (1) choose the "MFFI-Miner" algorithm, (2) select the input file "contextMFFIMiner.txt", (3) set the output file name (e.g. "output.txt"), (4) set the minsup parameter to 2, and (5) click "Run algorithm".
- If you want to execute this example from the command line, then execute this command:
java -jar spmf.jar run MFFI-Miner contextMFFIMiner.txt output.txt 2 in a folder containing spmf.jar and the example input file contextMFFIMiner.txt . - If you are using the source code version of SPMF, launch the file "MainTestMFFIMiner_saveToFile.java" in the package ca.pfv. SPMF.tests.
What is MFFI-Miner?
MFFI-Miner is an algorithm for mining fuzzy frequent itemsets in quantitative transactional database. In simple words, a quantitative transactional database is a database where items have quantities.
What is the input?
MFFI-Miner takes as input (1) a transaction database with quantity information and a minimum support threshold minSupport (a positive integer). Let's consider the following database consisting of 8 transactions (t1, t2, ..., t8) and 5 items (1, 2, 3, 4, 5). This database is provided in the text file “contextMFFIMiner.txt ” in the package ca.pfv.spmf.tests of the SPMF distribution.
Moreover, consider the membership function, shown below, which defines three ranges (low, medium, high).
Transaction ID |
Items |
Quantitates |
t1 |
3 4 5 |
3 2 1 |
t2 |
2 3 4 |
1 2 1 |
t3 |
2 3 5 |
3 3 1 |
t4 |
1 3 4 |
3 5 3 |
t5 |
1 2 3 4 |
1 1 2 1 |
t6 |
2 4 5 |
1 1 2 |
t7 |
1 2 4 5 |
4 3 5 3 |
t8 |
2 3 4 |
1 2 1 |
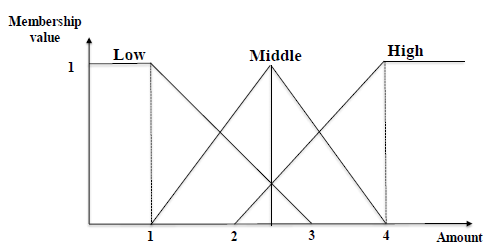
Fuzzy membership function
Why MFFI-Miner is useful?
Previous work on fuzzy frequent itemset mining used the maximum scalar cardinality to mine fuzzy frequent itemsets (FFIs), in which at most, only one linguistic term was used to represent the item in the databases. Although this process can reduce the amount of computation for mining FFIs, the discovered information may be invalid or incomplete. A gradual data-reduction approach (GDF) for mining multiple fuzzy frequent itemsets (MFFIs).The tree-based algorithm UBMFFP-tree suffered from building a huge tree structure. It mines FFIs with multiple fuzzy regions based on an Apriori-like mechanism. The MFFI-Miner algorithm efficiently mines MFFIs without candidate generation based on the designed fuzzy-list structure. This approach can be used to reduce the amount of computation and avoid using a generate-candidate-and-test approach with a level-wise exploration of the search space
Input file format
The input file format of MFFI-Miner is defined as follows. It is a text file. Each lines represents a transaction. Each line is composed of three sections, as follows.
- First, the items contained in the transaction are listed. An item is represented by a positive integer. Each item is separated from the next item by a single space. It is assumed that all items within a same transaction (line) are sorted according to a total order (e.g. ascending order) and that no item can appear twice within the same transaction.
- Second, the symbol ":" appears and is followed by the sum of the item quantities (an integer).
- Third, the symbol ":" appears and is followed by the quantity of each item in this transaction (an integer), separated by single spaces.
For example, for the previous example, the input file is defined as follows:
3 4 5:6:3 2 1
2 3 4:4:1 2 1
2 3 5:7:3 3 1
1 3 4:11:3 5 3
1 2 3 4:5:1 1 2 1
2 4 5:4:1 1 2
1 2 4 5:15:4 3 5 3
2 3 4:4:1 2 1
Consider the first line. It means that the transaction {3, 4, 5} has a total quantity of 6 and that items 3, 4 and 5 respectively have a quantity of 3, 2 and 1 in this transaction. The following lines follow the same format.
Output file format
The output file format of MFFI-Miner is defined as follows. It is a text file, where each line represents a frequent itemset. On each line, the items of the itemset are first listed. Each item is represented by an integer, followed by the letter "L", "M" or "H", and a single space. The letters L, M and H indicate if an item is in the Low, Medium or High Range of the fuzzy membership function, respectively. After, all the items, the keyword "#SUP:" appears, which is followed by a integer value indicating the support of that itemset.
3.H #SUP: 2.0
2.L #SUP: 4.0
2.L 3.M #SUP: 2.0
2.L 3.M 4.L #SUP: 2.0
2.L 4.L #SUP: 4.0
3.M #SUP: 3.3333335
3.M 4.L #SUP: 2.5000002
5.L #SUP: 2.5
4.L #SUP: 4.5
For example, the first line indicates that the itemset 3 in the high range of the fuzzy membership function (H) has a fuzzy value of 2.0. The other lines follows the same format.
Performance
MFFI-Miner is a very efficient algorithm. It uses a designed fuzzy-list structure to identify unpromising candidates early, and thus speed up the discovery of fuzzy itemsets.
Where can I get more information about the algorithm?
This is the article describing the MFFI-Miner algorithm:
Jerry Chun-Wei Lin, Ting Li, Philippe Fournier-Viger, Tzung-Pei Hong, Jimmy Ming-Thai Wu, and Justin Zhan. Efficient Mining of Multiple Fuzzy Frequent Itemsets[J]. International Journal of Fuzzy Systems, 2016:1-9.
Some other related papers:
T. P. Hong, G. C. Lan, Y. H. Lin, and S. T. Pan, An effective gradual data-reduction strategy for fuzzy itemset mining, International Journal of Fuzzy Systems, Vol. 15(2), pp.170-181, 2013. (GDF)
J. C. W. Lin, T. P. Hong, T. C. Lin, and S. T. Pan, An UBMFFP tree for mining multiple fuzzy frequent itemsets, International Journal of Uncertainty, Fuzziness and Knowledge- Based Systems, Vol. 23(6), pp. 861-879, 2015. (UBMFFP-tree)
For a good overview of frequent itemset mining algorithms, you may read this survey paper.