Download
There are two versions of SPMF:
- The source code version includes all the algorithms. It requires prior experience with Java for compiling the source code and running the examples.
- The release version provides a graphical
user interface and a command line interface,
and it is easy to use.
It offer all of the algorithms except a few exceptions.
| Source code version (342 algorithms + 190 tools) | Release version (313 algorithms + 77 tools) |
|
1) Download spmf.zip 2) Read the instructions for installing and running the source code: how_to compile source code and run it 3) After you have installed the source code, if you intend to modify the source code and/or reuse it in other Java projects, you may want to read the developer's guide, which provides information about the source code organization. Algorithms included: all the algorithms |
1) Download spmf.jar and the sample data files test_files.zip 2) If you want to use the graphical interface, follow these instructions: how_to_run_the graphical_interface If you want to use the command line interface, follow these
instructions: Algorithms included: all except CloStream,
estDec, estDec+, ItemsetTree, Memory-Efficient Itemset Tree,
ID3, and a few others |
If you have any questions, you may first have a look at the FAQ, and then ask your question in the data mining forum. If the question has to be private, you can send-me an e-mail.
If you want to use SPMF from programs written in other languages such as Python and R, you may call SPMF from the command line or use some unofficial wrappers for SPMF. A limitations of wrappers is that they may not support all algorithms from SPMF.
Release notes
- v 2.66 - 2026-06-15 (25 new algorithms, performance optimizations, new tools, bug fixes, user interface improvements)
- New algorithms
- the HTK-MINER and HTK-NEGFIN algorithms for top-k frequent itemset mining (thanks to original authors Malliaridis and Ougiaroglou, 2026 for providing a Java version for SPMF)
- the NAR-Miner algorithm for mining negative association rules with negative consequents (Bian et al., 2018).
- the PNAR-Eclat and PNAR-Apriori algorithms for mining positive and negative association rules of the general type (Cornelis et al., 2006)
- the MEHUIM and MEHUIM_Closed algorithms for mining high utility itemsets and closed high utility itemsets, respectively (thanks to Hongyang Yang, 2024).
- the META (Deng, 2009), MERIT+ (Le et al., 2013, DMERIT+ (Le et al., 2013), and MEI (Le, 2014) algorithms for erasable itemset mining
- the PFTree (Khairuzzaman et al., 2009) algorithm for periodic itemset mining using a FP-growth inspired approach
- the MTKPP (Amphawan et al., 2009) and TRCT (Amphawan et al., 2011) algorithms for top-k periodic itemset mining.
- the UVEclat (Leung et al., 2011) and UH-Mine ( Aggarwal et al., 2009) algorithms for uncertain itemset mining
- the TUFP algorithm (Le et al. 2020) for mining the top-k uncertain frequent itemset mining
- the WFIM (Yun et al., 2005) for mining frequent weighted itemsets with the weighted support
- the WIT-FWI, WIT-FWI-MOD and WIT-FWI-DIFF (Vo et al., 2013), NFWI (Vo et al., 2018),and NFWCI (Bui et al., 2021) algorithms for mining frequent weighted itemsets with the normalized weighted support.
- the UBTGEN and THUIsl algorithms (2024) (thanks to Srikumar Krisnamoorthy for providing the original source code).
- Tools
- Added a tool to automatically run scalability experiments comparing several algorithms. It is called the algorithm Performance_experiment_scalability in the user interface of SPMF.
- Added a tool to visualize frequent weighted itemsets (Visualize_Frequent_Weighted_Itemsets)
- Added a tool to generate a weight file containing random item weights for a given transaction database.
- User interface
- Improved the Graph Viewer for a better user interface and appearance.
- Improved the VisualPatternViewer so that it can now display frequent subgraphs. Also added pagination so that patterns are displayed on multiple pages if there are too many patterns, which improves efficiency.
- Improved the main window of SPMF for a better appearance and better performance: (1) a button for opening recent files, and choosing recent algorithms, (2) a new panel that shows the run history and allow to rerun an algorithm, (3) a redesigned output panel with more options for handling output files.
- Improved the WorkflowEditor to support branching nodes (more than one algorithm can be applied to the same output file). Added commands to load and save workflows (using a new file format). Moreover, I improved the function for validating the current workflow so that it is more comprehensive in finding issues with workflows. I also implemented new buttons to let the user reuse recent files and algorithms from previous runs.
- Added a CSV file viewer tool and a FASTA file viewer tool.
- Performance optimizations
and refactoring
- Optimized the algorithms AprioriTID, AprioriTIDClose, AprioriRare_TID and AprioriInverse_TID. In the source code, the new versions are in the package: ca.pfv.spmf.algorithms.frequentpatterns.aprioriTID_fast.
- Optimized the HMine and DefMe algorithms. In the source code, the new versions are in the package: ca.pfv.spmf.algorithms.frequentpatterns.hmine_fast, and ca.pfv.spmf.algorithms.frequentpatterns.defme_fast,
- Optimized the DCI_Closed implementation. It now takes a percentage minimum support as input. In the source code, the new version is in the package: ca.pfv.spmf.algorithms.frequentpatterns.dci_closed_fast.
- Other optimizations in various classes of SPMF.
- Bug fixes:
- Fixed the problem in the GUI that AprioriTIDBitset was calling AprioriTID.
- Fixed an inaccurate console message for AprioriTIDRare.
- Fixed a small bug in PFPM that could lead to support 0 patterns in extreme cases.
- Fixed a bug in Eclat introduced in v2.65.
- Fixed a bug in the generation of association rules with lift (thanks to Yuji Uchiyama for reporting the bug)
- Fixed a bug in TKQ (some patterns with two items appeared twice in some case). Thanks to Tai Dinh for reporting it.
- Other modifications :
- Changed the output format of UApriori to output the expected support of each discovered itemset while not showing a value for each item as it is difficult to interpret for the user.
- Removed an extra space before #LOSS: in the output of VME, and now the loss is a double value instead of an integer in the output, to be more precise.
- Known issues:
- There is a bug in the UP-Span implementation such that it can miss some patterns (thanks to Acquah Hackman for reporting it). For example, on contextHUE_Span.txt, minutil = 0.45 and maxWindow =2, the pattern 2 -1 1 3 -1 #UTIL: 10 is missing from the results of UP-Span. But this pattern can be found by HUE-SPAN and if we check by hand, this pattern does exist in the database. By the way, to compare the results of HUE-SPAN with UP-Span it is necessary to use maxWindow+1 for HUE-SPAN and set UseTraditionalUtility = true in the user interface or checkMaximumUtility = false in the source code version.
- These is a bug in the BIDE+ implementation such that some incorrect results may be obtained for sequences with multiple items per itemset.
- There is a bug in the LAPIN implementation such that some errors may be produced in some specific scenarios.
- New algorithms
- v2.65 - 2026-02-18 (8 new algorithms, 3 new tools, performance optimizations, bug fixes)
- New algorithm(s)
- the LinearTable algorithm for mining frequent itemsets, which can work especially well when the number of items is relatively small. This algorithm has very low memory usage in some cases (Lu et al. 2023)
- The SAM algorithm for mining frequent itemsets (Borgelt et al., 2009)
- The TM algorithm for mining frequent itemsets (Song et al., 2006)
- The NEWCHARM algorithm for mining frequent closed itemsets (Ye et al., 2015)
- The DBVMiner algorithm for mining frequent closed itemsets (Vo et al., 2012)
- The FTARM algorithm for top-k association rule mining, which is a variation of ETARM with additional strategies (Liu et al., 2019)
- The ETARM algorithm for top-k association rule mining, which is a variation of TopKRules with additional pruning strategies (Nguyen et al., 2017)
- The AprioriTID_HD algorithm, a modification of AprioriTID for better performance (thanks to Harshil Damania for proposing this improvement )
- Performance optimizations:
- Optimized Apriori, AprioriClose, AprioriInverse, AprioriRare, AprioriTopK with advanced optimizations such as a hash-tree, transaction merging and removing inactive items after each iteration, bitset-based subset checking, and renaming items for fast item comparisons. In the source code, these new versions are in the package: ca.pfv.spmf.algorithms.frequentpatterns.apriori_fast..
- Optimized association rule generation with Apriori by using the new Apriori implementation
- Optimized sporadic association rule generation using the optimized AprioriInverse implementation
- Optimized the Relim algorithm. It has now competitive performance with several other frequent itemset mining algorithms on some datasets.
- Further optimized the Eclat, dEclat, Charm and dCharm algorithms.
- Optimized the TopkRules, TopkClassRule algorithms using a bitset pool to manage bitset allocation and to count support using a vertical database instead of horizontal database.
- Tool(s) for data processing
- Added a tool to sample records from a dataset in SPMF format (text files) where each line is a record using different type of sampling (resevoir, seed, etc.).
- Added a tool to remove duplicated records from a dataset in SPMF format (text files) where each line is a record.
- User interface
improvements
for visualizations
- Added a new visualization tool called the Itemset-Item Matrix Viewer.
- Added a tool "Measure Histogram Viewer" and histogram of "Size distribution" in the Visual Pattern Viewer.
- Added a tool to view item co-occurrences as a heatmap in the Transaction Database Viewer, and other dataset viewer tools.
- Improved the user interface of the histogram viewer panel used by different tools in the GUI of SPMF.
- Improved the user interface of the TransactionDatabaseViewer, UncertainTransactionDatabaseViewer and other dataaset viewers to include a "summary statistics" panel.
- Bug fixes:
- Fixed a bug in the compare() method used by TopKRules and TopKClassRules, that could result in some rare issues.
- Fixed a bug in the dCharm algorithm with the hash function used for checking if there are supersets. This could cause some non-closed itemsets to be output in some rare cases..
- Removed the feature of outputing the list of transactions IDs for dEclat, dCharm and dCharm_bitset since it does not work for diffsets.
- Fixed a bug in AprioriHT such that some itemsets may be missed when the branch count was too small.
- Fixed a bug in the HistogramViewer such that the combo box was overlapping with buttons.
- Known issues:
- There is a bug in the UP-Span implementation such that it can miss some patterns (thanks to Acquah Hackman for reporting it). For example, on contextHUE_Span.txt, minutil = 0.45 and maxWindow =2, the pattern 2 -1 1 3 -1 #UTIL: 10 is missing from the results of UP-Span. But this pattern can be found by HUE-SPAN and if we check by hand, this pattern does exist in the database. By the way, to compare the results of HUE-SPAN with UP-Span it is necessary to use maxWindow+1 for HUE-SPAN and set UseTraditionalUtility = true in the user interface or checkMaximumUtility = false in the source code version.
- These is a bug in the BIDE+ implementation such that some incorrect results may be obtained for sequences with multiple items per itemset.
- There is a bug in the LAPIN implementation such that some errors may be produced in some specific scenarios.
- New algorithm(s)
- v2.64b - 2025-12-6 (8 new algorithms, bug fix) (archive: spmf2.64.zip and spmf2.64.jar)
- New algorithm(s)
- The HMP-SA algorithm for discovering compressing itemsets in a transaction database using a simulated annealing approach (Chen, E. et al., 2026).
- The HMP-HC algorithm for discovering compressing itemsets in a transaction database using a hill-climbing approach (Chen, E. et al., 2026).
- the GENMAX algorithm for mining frequent maximal itemsets from a transaction database (Gouda et al., 2005)
- the DIC algorithm for mining frequent itemsets in a transaction database using dynamic itemset counting (Brin et al. 1997)
- the Talky-G and Talky-G-Diffset algorithms for mining frequent generator itemsets in a transaction database (Szathmary, 2009)
- the iMEFIM algorithm for high utility itemset mining, a variation of EFIM that can be faster but may consume more memory (Nguyen et al., 2019)
- the PUCPMiner algorithm for high utility itemset mining, a variation of FHM with a potentially tighter upper bound (Patel et al., 2022), obtained under the GPL license from the repository of Rashmin Gajera (github.com/rashmin-gajera)
- New tools(s)
- the Pattern Diff Viewer tool, a new window in the Graphical User Interface for comparing two files containing patterns to identify difference between patterns (contrast patterns).
- Bug fix:
- Fixed the bug in CHUI-Miner Max such that in some rare cases some non maximal itemsets were output.
- New algorithm(s)
- v 2.64 - 2025-11-29 (5 new algorithms, additional features and improvements)
- New algorithm(s):
- The HMG_GA algorithms for discovering compressing sequential patterns in genome sequences using a genetic algorithm (M. Z. Nawaz et al., 2025)
- The HMG_SA algorithms for discovering compressing sequential patterns in genome sequences using simulated annealing (M. Z. Nawaz et al., 2025)
- The GRIMP algorithm for discovering compressing itemsets in a transaction database using a genetic algorithm (M. Z. Nawaz et al., 2025).
- The CARPENTER algorithm for mining frequent closed itemset in a transaction database using row enumeration, which is suitable for datasets with very long transactions (Pan et al., 2003)
- The CARPENTERMax algorithm for mining frequent maximal itemsets by postprocessing after applying CARPENTER (Pan et al., 2003).
- New tool(s):
- Added a tool to export the metadata about all algorithms from SPMF as a JSON file spmf.json. This will help interoperability with other software. This tool is called Export_algorithms_list_to_JSON and is available in the GUI of SPMF as well as in the command line interface.
- Added a new tool in the GUI of SPMF called the Algorithm_Graph_Visualizer to visualize similar algorithms in terms of input and output or categories as a graph.
- Improvements:
- Improved various graphical interface components such as the MemoryViewer, HistogramViewer, GraphViewer and SPMF Text Editor by fixing a few bugs and adding new features.
- Added a new mode in the TransactionDatabaseViewer to view transactions either as lists or as columns.
- New algorithm(s):
- v 2.63 - 2025-07-01
(major version, 6 new algorithms, 2 new tools, several bug fixes )
- New algorithms:
- The EMDO algorithm for mining frequent parallel episodes and episode rules in complex event sequences by counting distinct occurrences (thanks to Oualid Ouarem et al. for the original code).
- the EMDO-Rules for generating episode rules from parallel episodes found by EMDO. (Ouarem et al., 2024)

- The RMiner algorithm for high utility itemset mining (thanks to Pushp Sra et al. for the original code).
- The ScentedUtilityMiner algorithm for high utility itemset mining with a recency constraint using reinduction counters (thanks to Pushp Sra et al. for the original code).
- The Density Peak Clustering (DPC) algorithm for clustering vectors of numbers
- The AEDBScan algorithm for clustering vectors of numbers
- New tools:
- A tool (VisualPatternViewer) to visualize patterns (screenshot). It works with patterns discovered by most algorithms such as itemsets, sequences, episodes and association rules. This tool can be used in the graphical interface of SPMF by selecting for "Open output file using" the option and then "Visualize (pattern type) " . This option is available for most algorithms with a few exceptions.
- A tool (TaxonomyViewer) (screenshot) to visualize a taxonomy file as used by algorithms such as CLH-Miner.
- Bug fixes:
- Fixed a bug in the output format of HUSRM such that tabs where used instead of spaces, which caused some problems when using the pattern viewer (thanks to Guilherme Namen for reporting the problem).
- Fixed a bug in the workflow editor such that some algorithms where marked as unsuitable in the combobox (in light grey color).
- Fixed the output format of MINEPI so that it is consistent with other algorithms (#SUP: instead of #SUP :)
- Fixed the output format of EFIM-CLOSED to add a space before #UTIL: so that it is consistent with other algorithms
- Fixed the output format of HGB and HGB-ALL to replace an invisible tab character by a space to make it consistent with other algorithms.
- Fixed the DescriptionOfAlgorithm for various algorithms to ensure that the information is correct and consistent among different algorithms for their output.
- Fixed the output format of PHUI-Miner and LHUI-MINER to make it consistent with other algorithms using #WINDOWS: followed by the windows
- Fixed the output format of LTHUI-Miner to make it consistent with other algorithms. It is now #PERIOD-UTIL-SLOPE: instead of #PERIOD-UTIL-SLOPE
- Fixed a bug in the usage of the PPFP algorithm in the GUI version of SPMF such that parameters were incorrectly used.
- Fixed the output format of LPP-Growth, LPPM-Breadth and LPPM-Depth to make it more consistent with other algorithms, removing an extra space, and changing #Time-intervals: to #TIME-INTERVALS:.
- Fixed a bug for the usage of NPFPM through the user graphical interface of SPMF. Some parameters were incorrectly parsed.
- Fixed the description of the Pascal algorithm inside SPMF so that its output is correctly named.
- Fixed the output of the Pascal algorithm to make it consistent with other algorithms ( #IS_GENERATOR is replaced by #IS_GENERATOR: )
- Fixed a problem in the output format of ProSeCo (missing space after -1)
- Fixed a bug in the timeline viewer when used for viewing files such as contextEMMA.txt
- Fixed a bug in the GUI for the MaxSP algorithm such that the minsup parameter was rounded down instead of rounded up.
- Documentation
- Fixed some typos and small errors in the documentation.
- Fixed the missing links for the examples of the AERMiner and SKOPUS algorithms in the documentation on the SPMF website.
- Fixed the broken url of the documentation for OWSP-Miner on the website.
- New algorithms:
- v 2.61 - 2.62 - 2024-6-12
- 15 new tool(s) to calculate statistics about datasets:
- A new tool to calculate statistics about a product transaction database
- A new tool to calculate statistics about a sequence database with cost and binary utility
- A new tool to calculate statistics about a sequence database with cost and numeric utility
- A new tool to calculate statistics about a sequence database with utility
- A new tool to calculate statistics about a time-extended sequence database
- A new tool to calculate statistics about a transaction database with cost and utility
- A new tool to calculate statistics about a transaction database with utility and period information
- A new tool to calculate statistics about a transaction database with utility and timestamps
- A new tool to calculate statistics about an event sequence
- A new tool to calculate statistics about an interval sequence database
- A new tool to calculate statistics about a multi-dimensional sequence database
- A new tool to calculate statistics about a multi-dimensional sequence database with timestamps
- A new tool to calculate statistics about an uncertain transaction database
- A new tool to calculate statistics about a file with double vectors (instances) for clustering
- A new tool to calculate statistics about time series
- Improvements to existing features
- Workflow editor: added a menu for exporting a workflow as a BAT or SH scripts for Windows and Linux, respectively.
- Log console in the SPMF GUI: Modified the contextual menu to add the option of changing the font size and saving the current log to a file.
- Modified the progress bar of the GUI to display the time since an algorithm has been launched.
- Datasets:
- Added sequence of API calls of malware programs to the "Datasets" page of the SPMF website.
- Added four customer shopping datasets: instacart_prior, insta_cart_train, TH1 and TH2. TH2 is the largest with about 26 million transactions. The Instacart datasets are interesting as they also include a taxonomy with categories of items, and item names.
- Bug fix(es)
- Fixed a bug in the tool for calculating stats about a sequence database such that it did not handle file containing lines starting with the character @.
- Fixed a bug in the progress bar of the developer tool for checking broken links from the SPMF documentation.
- Fixed a bug with the choice "Don't open" for opening the output file in the user interface of SPMF. It was displaying an error.
- Fixed a bug in VertTIRP and FastTIRP in the use of the maxGap constraint.
- Fixed a bug in the new ConsolePanel of the GUI of SPMF such that the console output was sometimes not displayed after using the tool to run experiments. And also fixed a bug that when an algorithm was run as an external process, the console output was not shown in the console panel.
- Fixed some display issue for low-resolution screens.
- Fixed the console of SPMF so that it autoscroll to the last line.
- Code improvements:
- Fixed some warnings, some potential resource leaks, and rewrote some code that was using deprecated methods.
- 15 new tool(s) to calculate statistics about datasets:
- v 2.60 - 2024-4-20 - major version - 18 new algorithms, 21 new viewer tools, 8 bug fixes, several graphical user interface improvements, new tools, etc.
- New algorithm(s)
- the MRI-CE algorithm (2024) for mining minimal rare itemsets using the cross-entropy method (thanks to Song. et al. for providing the source code of the original implementation)
- the FastTIRP (2022) for discovering frequent time-interval related patterns in sequences of events described using time intervals.
- the VertTIRP (2021) for discovering frequent time-interval related patterns in sequences of events described using time intervals.
- the KRIMP (2011) algorithm for discovering compressing itemsets in a transaction database.
- the SLIM (2012) algorithm for discovering compressing itemsets in a transaction database.
- the MAPD algorithm (Wu, Y. et al., 2014) for mining frequent sequential patterns with periodic wilcard gaps in a sequence of characters (thanks to Wu et al. for providing a Java conversion of the original code)
- the OWSP-Miner algorithm (Wu, Y. et al., 2022) for mining self-adaptive one-off weak-gap strong sequential patterns in a sequence of characters (thanks to Wu et al. for providing a Java conversion of the original code)
- the K-Mean++ algorithm for discovering clusters.
- the FP-Growth(top-k) algorithm, which is a variant of the SPMF version of FP-Growth to find the top-k frequent itemsets.
- the Apriori(top-k) algorithm, which is a variant of the SPMF version of Apriori to find the top-k frequent itemsets.
- the ETAUIM algorithm (2023) for mining the top-k high average utility itemset using a breadth-first search (obtained from Github @liuxuan605 based on the use of code derived from SPMF under the GPL license)
- the ECHUM algorithm (2022) for mining correlated high utility itemsets using the Kulczynski correalation measure (obtained from Github @aman955 under the GPL license)
- the EMSFUI-D and EMSFUI-B algorithms (2022) for mining the skyline frequent-utility itemsets (obtained from Github @liuxuan605 based on the use of code derived from SPMF under the GPL license)
- the FUIMTF-Tree and FUIMTWU-Tree algorithms (2022) for mining frequent-utility itemsets (obtained from Github @liuxuan605 based on the use of code derived from SPMF under the GPL license)
- the PHMN and PHMN+ algorithms (2023) for mining periodic high utility itemsets with positive or negative utility ( obtained from Github @Laughing1999 under the GPL license)
- New GUI tools to view different types of datasets:
- A simple tool to view the content of an ARFF file
- A new tool to view the content of an an event sequence file
- A new tool to view a sequence database cost binary utility file
- A new tool to view a sequence database cost numeric utility file
- A new tool to view a sequence database file
- A new tool to view a time-extended sequence database
- A new tool to view a multi-dimensional sequence database
- A new tool to view a multi-dimensional time sequence database
- A new tool to view a sequence utility database file
- A new tool to view a cost utility transaction database file
- A new tool to view a transaction database file
- A new tool to view an uncertain transaction database file
- A new tool to view a utility transaction database file
- A new tool to view a utility time transaction database file
- A new tool to view a utility period transaction database file
- A new tool to view a product transaction database file
- A new tool to view a sequence database file with time intervals
- New tool(s) to generate synthetic datasets:
- A new tool to generate synthetic datasets for clustering
- New tool(s) for data transformation:
- A new tool to fix a sequence database file (such as repeated items in an itemset). The tool is called "Fix_a_sequence_database" in the GUI and command line interace of SPMF.
- A new tool to fix item ids in a transaction database with utility information
- New tool(s) to calculate statistics about datasets:
- New GUI tool(s):
- A new tool called the MemoryViewer to monitor the memory usage of the JVM when using SPMF.
- A new tool called the Workflow Editor to create and edit workflows (a set of algorithms to be executed one after the other).
- A new tool in the source code of SPMF called the "PreferencesViewer" in the package "ca.pfv.spmf.gui;" that allows to visualize the data (your preferences) stored by SPMF in the registry of your computer. It includes a button to reset the preferences to their default value. This tool is not accessible from the main interface of SPMF.
- A new developers' tool window for developers of SPMF
- A new tool to download an offline copy of the SPMF documentation on your computer
- New data structure(s) for developers:
- A collection of data structures optimized for primitive data types in the package ca.pfv.spmf.datastructures.collections. It includes optimized implementations of List, Map, Set, LinkedList and Comparator for primitive types. Using these can reduce the memory usage and provide a speed up when implementing some new algorithms.
- Improvement(s) to existing features
- Cleaned the source code of the user interface of SPMF and improved several aspects for a better design. For instance, the parameters of each algorithm are now entered by the user using a table, and the main window of SPMF is now updated so that components are layed out using relative positions rather than fixed X,Y positions.
- Modified the Pattern Viewer tool of spmf to allow visualizing the distributions of patterns found by an algorithm as a frequency histogram.
- Improved the Graph viewer.
- The cursor is now changing when the mouse is over a node. Besides, the Fruchterman-Reingold automatic layout for graphs has been improved using a grid optimization (thanks to Zevin Shaul).
- Implemented the Rectangle graph layout
- Modified K-Means to use a random selection of instances as initializations to follow the more standard approach.
- An improved MemoryLogger class, that now has two new functions "startRecordingMode" and "stopRecordingMode" to record values collected by the MemoryLogger to a file. This is useful for evaluating the memory performance of algorithms.
- New datasets:
- Added time-interval sequence datasets that can be used with algorithms like FastTIRP and VertTIRP
- Bug fix(es)
- Fixed a bug in VMSP for the maxgap constraint (thanks to Alexandre Vernotte for reporting the bug) and a related issue in VGEN.
- Fixed a bug in the Database.java class of the TNR algorithm that cause some issues on some input files (thanks to Huan Yang for finding and fixing the bug).
- Fixed a format problem with the OnlineRetail_II_best dataset, which caused problems for some sequential pattern mining algorithms. The file had some problem and has been fixed. Thanks to Suzuki Shota for reporting the problem.
- Fixed a bug in the NONEPI algorithm such that some patterns may be missed (thanks to Zefen Chen for reporting the bug).
- Fixed a bug in the NOSEP algorithm when using the minlen constraint (thanks to M. Zivanovic for reporting the bug).
- Fixed a bug in the class AlgoInstanceFileReader that could cause some errors in clustering algorithms and the display of clusters by the cluster viewer
- Fixed a bug in the SPMF text editor such that the interface was sometimes not updating properly when the font size or font family was changed by the user.
- Fixed the output of the AlgoSFUPMinerUemax algorithm so that #UTIL: is used instead of #UTILITY to be consistent with the outpout of other algorithms
- v 2.59 2022-12-25
(3 new algorithms + 2 new tools + bug fix)
- New algorithms:
- the PPFP algorithm to discover productive periodic frequent itemsets in a transaction database (a list of transactions) (thanks to Vincent Nofong for providing and integrating the original code)
- the NPFPM algorithm to discover non-redundant periodic frequent itemsets in a transaction database (a list of transactions) (thanks to Vincent Nofong for providing and integrating the original code)
- the SRPFPM algorithm to discover self-reliant periodic frequent patterns in a transaction data base (thanks to Vincent Nofong for providing and integrating the original code)
- New tools in SPMF's GUI:
- A new tool called "Algorithm Explorer" to explore the collections of algorithms offered in SPMF. It is a window with a tree where algorithms are classified by category and where information can be obtained about an algorithm by clicking on it. Moreover, there is a function to search for similar algorithms with the same input/output file types and mandatory parameters.
- A new tool called "Graph Viewer" to view graph files and subgraphs found by algorithms such as gSpan, cgSpan and TKG. This tool is working but some improvements will likely be made in the next versions to add more features such as zooming, etc.
- Improvements:
- Improved the transaction and database classes of the TopKRules and TopKClassRules algorithms to reduce memory usage for very large databases (thanks to Zevin Shaul)
- Bug fix
- Fixed a bug in VGEN such that some patterns could be missed when using the maxgap (thanks to Darrell Conklin for reporting the problem).
- New algorithms:
- v 2.58b 2022-11-30 (6 new algorithms + user interface improvements )
- New algorithms:
- the HUCI-Miner algorithm to mine closed high utility itemsets and generators at the same time (thanks to Jayakrushna Sahoo et al. for the original code )
- the FHIM algorithm to mine all high utility itemsets (thanks to Jayakrushna Sahoo et al. for the original code)
- the HGB algorithm to mine non redundant high utility association rules (thanks to Jayakrushna Sahoo et al. for the original code)
- the HGB-all algorithm to derive all high utility association rules from the non redundant high utility association rules (thanks to Jayakrushna Sahoo et al. for the original code)
- algorithms for mining sequential patterns with flexible constraints in a time-extended sequence database (eg. MOOC data)
- the SPM-FC-L algorithm (Thanks to Wei Song et al. for the original code)
- the SPM-FC-P algorithm (Thanks to Wei Song et al. for the original code)
- An improved multi-thread implementation of the cGSPAN algorithm for mining the closed subgraphs in a graph database, and also a version to mine subgraphs in a single graph using the MNI support measure (thanks to Zevin Shaul for this great work!)
- New features for the GUI::
- An integrated text editor called "SPMF text editor" is added to SPMF. It can be used as an alternative to the default system text editor to open the output files generated by data mining algorithms. This text editor is lightweight and tailored for this task. It has a night mode, search bar, and other features.
- The GUI of SPMF now opens in the middle of your screen. This is useful if you are frequently connecting to screens with different resolutions.
- In the GUI of SPMF, categories of algorithms are now displayed with colors in the JComboBox of algorithms to make it easier to select an algorithm for the user.
- New dataset(s):
- The mooc.txt dataset, which contains over 80,000 sequences with timestamps from a Chinese e-learning platform. Each sequence from that dataset is a list of events with timestamps indicating the enrollment of a student in different online courses. This dataset was transformed to SPMF format by Wei Song et al., and is now available in the datasets page of this website.
- New algorithms:
- v 2.57 2022-10-21 (1 new algorithm)
- New algorithms:
- The HUIM-ACO algorithm for mining high utility itemsets using ant-colony optimization (Thanks to Wei Zong and Jiakai Nan for the original code).
- New algorithms:
- v 2.56 2022-10-5
(10 new algorithms)
- New algorithms:
- The NONEPI algorithm for mining episode rules in an event sequence using the non-overlapping frequency (original implementation by Farid Nouioua, Oulaid Ouarem, et al).
- The LCIM algorihtm for mining the low cost high utility itemsets from a transaction database with utility and cost information (original implementation by Saqib Nawaz et al.)
- The MaxFEM algorithm for mining the maximal frequent episodes in an event sequence (based on the head support).
- The AFEM algorithm for mining the frequent episodes in an event sequence (based on the head support).
- The AFEM-Rules algorithms for deriving episode rules from the output of AFEM.
- The IncCHUI algorithm for incrementally discovering the closed high utility itemsets (code obtained from Dam et al., and included based on the GPL license)
- The CLS-Miner algorithm for mining closed high utility itemsets (code obtained from Github user "limuhangk" under the GPL license, as it contains GPL code from SPMF)
- The HMiner_Closed algorithm for mining closed high utility itemsets (code obtained from Github user "limuhangk" under the GPL license, as it contains GPL code from SPMF)
- The HUIM-SU algorithm for mining high utility itemsets (code obtained from Github under the GPL license, as it contains GPL code from SPMF)
- The THUI algorithm for mining the top-k high utility itemsets (thanks to Srikumar Krishnamoorty for providing the original code)
- New dataset(s)
- Added real transactions datasets with both cost and utility values to the datasets page. These datasets can be with the LCIM algorithm.
- New algorithms:
- v 2.55 2022-7-10
- Bug fix(es)
- Modified the definition of perfectly rare itemsets in AprioriInverse so that an itemset is rare if < maxsup instead of <= maxsup. This is a small tweak that makes sense to avoid the case that a rare itemset may be a frequent itemset as well.
- Bug fix(es)
- v 2.54 2022-6-5 (1 new algorithm + features for experiments)
- New tool for running performance experiments:
- ExperimenterForParameterChange: A new tool to automatically run experiments where one or more algorithms are run on a dataset and a parameter is varied. This tool is useful for writing research papers as it can output results in a tab-separated format that can be easily imported into spreadsheets like Excel to draw charts, and also can generate PGFPlots that can be used directly in Latex documents. This can save a lot of time for carrying out performance experiments. See the documentation for more details.
- Two new features in the GUI of SPMF:
- Run an algorithm as a separated process. If this option is activated, when the user clicks "Run algorithm" in the GUI, the algorithm will be run in a separated virtual machine instead of a thread in the same virtual machine. Running an algorithm in a separated virtual machine is very useful when doing performance experiments as it allows to make sure that the memory usage is reset every time that an algorithm is run, to get accurate results.
- Time limit of X seconds. If this option is activated, an algorithm will be automatically stopped if it runs for more than X seconds.
- New dataset(s):
- A new dataset called Chicago_Crimes_2001_to_2017, which can be used for high utility itemset mining and frequent itemset mining (Thanks for Zhongjie Zhang for providing the conversion from this UCI dataset).
- A new dataset called YooChoose, which was obtained from RecSys2015 and transformed to SPMF format. It is suitable for frequent itemset mining and high utility itemset mining. But it is a very sparse dataset and does not contain item names, so it may not always be appropriate.
- Bug fix(es):
- A bug was fixed such that the output of the TKO algorithm was empty when using the graphical user interface of SPMF (thanks to Jose Maria Luna for reporting it).
- New tool for running performance experiments:
- New algorithm(s)
- An implementation of the cGSPAN algorithm for mining the closed subgraphs in a graph database (thanks to Zevin Shaul)
- An implementation of the FEACP algorithm for cross-level high utility itemset mining (thanks to N.T Tung, Bay Vo et al.)
- An implementation of binary logistic regression using gradient descent for binary classification using vectors of continuous values as features (only available in the source code for now, documentation will be added later).
- v 2.52 2022-2-10 (3 new algorithms)
- New algorithm(s)
- The TKU-CE algorithm for heuristically mining the top-k high-utility itemsets with cross-entropy (thanks to Wei Song, Lu Liu, Chuanlong Zheng et al., for the original code)
- The TKU-CE+ algorithm for heuristically mining the top-k high-utility itemsets with cross-entropy with optimizations (thanks to Wei Song, Lu Liu, Chuanlong Zheng et al., for the original code)
- The TKQ algorithm for mining the top-k quantitative high utility itemsets (thanks to Nouioua, M. et al., for the original code)
- Other modifications:
- Some refactoring of the code of FHUQI-Miner was done to share some code with TKQ.
- Bug fix:
- Fixed a bug in HUSRM (thanks to Lili Chen et al. for reporting the bug and a fix)
- Datasets
- 4 new datasets for sequence pattern mining are added called E-Shop, MicroblogPCU, OnlineRetail_II_all and OnlineRetail_II_best (thanks to Frederic Flouvat). More information about these datasets are available on the datasets page. These datasets are especially interesting because they contain sequences of itemsets instead of sequence of items.
- New algorithm(s)
- v 2.51 2022-1-25 (2 new algorithms)
- New algorithm(s)
- The SFU-CE algorithm for mining skyline frequent high utility itemsets using the cross-entropy method (thanks to Wei Song, Chuanlong Zheng et al., for the original code)
- The POERMH algorithm for mining partially ordered episode rules in a sequence of events, using the head support (thanks to Yangming Chen et al. for the original code)
- Bug fixes:
- Fixed a bug in gSpan and TKG such that the result could be incorrect when the skip strategy optimization was activated (Thanks to Zevin Shaul for reporting the problem)
- New algorithm(s)
- v 2.50 2021-12-11 (2 new algorithms, bug fixes)
- New algorithms
- The SFUI_UF algorithm for mining skyline utility itemsets using utility filtering (thanks to Wei Song, Chuanlong Zheng et al., for the original code)
- The HAUIM-GMU algorithm for mining high average utility itemsets (thanks to Wei Song, Lu Liu, et al. for the original code)
- Bug fixes
- Fixed a small bug in LHUI-Miner and PHUI-Miner where > minutil was used instead of >= minutil (thanks to Acquah Hackman for reporting it)
- New algorithms
- v 2.49 2021-8-15 (11 new algorithms)
- New algorithms:
- 1 new algorithm (HUIM-AF) for mining high utility itemsets using the artificial fish swarm algorithm (thanks to Wei Song, Junya Li et a. for providing the original code)
- 9 new association rule-based algorithms have
been added to perform classification using association
rules.
Those algorithms are ACAC, ACCF, ACN, ADT, CBA, CBA2, CMAR, L3 and MAC.
Implementations of these algorithms were obtained from the LAC project of Padillo, F., Luna, J.M., Ventura, S. under the GNU GPL3 license (github.com/kdis-lab/lac). That code was already based on some code from SPMF such as Apriori, Eclat and Charm. Several improvements were made to the code of LAC before integrating in SPMF. Some of the key improvements are:
(1) added code to save a trained classifier to file using serialization and load it to memory, (2) added a function to save rules to a file as text for readability, (3) refactored the code to improve the design, (4) added several optimizations to avoid creating unecessary objects and reduce the complexity of some operations, (5) removed some external dependencies not useful for SPMF, (6) added code to read the input format of SPMF in addition to the ARFF format, (7) changed the internal representations of items to make it consistent with SPMF (starting from 0 instead of 1), (8) reorganized all rule-based classifiers as subclass of RuleClassifier, which is a subclass of Classifier, (9) added many comments, (10) changed several class and package names to make it consistent with the standards of SPMF, (11) replaced the usage of clone() by copy constructors as using clone() is not recommended and this has allowed further refactoring of the code.
Besides, (11) I have written new code to run experiments to compare classifiers. The code for experiment support not only support holdout but also k-fold cross-validation. The redesigned framework for experiments also create output that is tab-separated so that it can be directly copied to Excel. - 1 new implementation of the KNN algorithm that can be compared with rule-base classifiers.
- Refactoring
- I have redesigned the code of ID3 so that it
can be compared with the above rule-based classifiers
- I have redesigned the code of ID3 so that it
can be compared with the above rule-based classifiers
- New algorithms:
- v 2.48 2021-6-28 (2 new algorithms)
- New algorithms:
- the HUIM-SPSO algorithm for mining high utility itemsets using Set-based Particle Swarm Optimization (thanks to Wei Song and Junya Li for providing the original code)
- the NEclatClosed algorithm for mining frequent closed itemset (thanks to Nader Aryabarzan)
- New algorithms:
- v 2.47 2021-5-28 (8 new algorithms)
- New algorithms:
- the LPP-Growth, LPPM-Breadth and LPPM-depth algorithms for discovering local periodic patterns in a transaction database or sequence of transactions (thanks Peng Yang et al. )
- the HUIM-HC algorithm for mining high utility itemsets using hill-climbing (thanks to Saqib Nawaz et al.)
- the HUIM-SA algorithm for mining high utility itemsets using simulated annealing (thanks to Saqib Nawaz et al.)
- 3 post-processing algorithms to generate standard episode rules from frequent episodes found by the TKE, EMMA and MINEPI+ algorithms (thanks to Yangming Chen)
- v.2.46 2021-4-10 (1 new
algorithm)
- New algorithms:
- The NOSEP algorithm for mining non overlapping sequence patterns with gap constraints in one or more sequences (strings. Thanks to Youxi Wu et al. for providing a Java conversion of his original C++ implementation.
- New algorithms:
- CLH-Miner for mining cross-level high utility itemsets (thanks to Bay Vo et al. for the efficient implementation)
- FHUQI-Miner, state-of-the-art algorithm for mining high utility quantitative itemsets (by Mourad Nouioua et al.)
- POERM and POERM-ALL algorithms for mining partially ordered episode rules in a sequence of events (by Yangming Chen et al. )
- New dataset:
- COVID-19 genome sequence dataset in SPMF format (prepared by Saqib Nawaz; see paper ). This dataset can be used for sequential pattern mining and sequential rule mining.
- Datasets for high utility quantitative itemset mining (to be used with FHUQI-Miner and VHUQI)
- Bug fix/Improvements:
- Fixed a bug so that the confidence of CMRules was incorrectly displayed in the output file (the confidence was saved instead of the sequential confidence) (thanks to Ludwig Zellner for fixing the bug)
- Improved the implementation of VHUQI and fixed a bug in VHUQI such that the output was wrong in some case. Also the input format was adapted to make it more simple and the same as FHUQI-Miner (thanks to Mourad Nouioua)
- New algorithms:
- v.2.44 2021-2-12 (4 new
algorithms, bug fixes, new datasets, tools and features)
- New algorithms
- LTHUI-Miner for mining the locally-trending high utility itemsets (by Yanjun Yang et al.)
- MLHUI-Miner for discovering the multi-level high utility itemsets using a taxonomy (implemented by Ying Wang et al.)
- AER-Miner for mining attribute evolution rules in a dynamic attributed graph (by Ganghuan He et al.)
- TSPIN for mining the top-k stable periodic patterns in a transaction database (a sequence of events with or without timestamps) (by Ying Wang, Peng Yang et al.)
- Bug fixes
- Fixed a small bug in DFIN (thanks to Nader Aryabarzan)
- Fixed a bug in the user interface for TKG (thanks to..)
- Fixed a small error in the DB_LHUI.txt example file
- Datasets
- Fruithut : a shopping dataset with utility and taxonomy information
- Liquor: a shopping dataset with utility and taxonomy information
- Fixed some problem in the Ecommerce dataset that some items were appearing twice in the same transaction (which should not have happened)
- Tools
- Added a new tool to fix problems in transactions databases with time and utility information (used it to fix the Ecommerce dataset). This tool is the algorithm called "Fix_a_transaction_database_with_utility_time" in the user interface. It makes sure that no item appears twice in a same record (transaction) and that the total utility of each transaction is correctly calculated.
- Features
- Added a feature with example for saving or loading a trained sequence prediction model from file (for the AKOM, DG, TDAG, LZ78, PPM, CPT, and CPT+ algorithms)
- New algorithms
- v 2.43- 2020-3-20 (add features to algorithms)
- New algorithm
- The DFI-List algorithm for recovering all frequent itemsets from frequent closed itemsets
- Bug fix
- Remove a double space before #SUP: in the output of TKS (thanks to Tom for reporting this issue)
- New algorithm
- v 2.42c- 2020-3-19 (add features to algorithms)
- Added the possibility of specifying a minimum pattern length for the FPGrowth and RPGrowth algorithms.
- Added the possibility of specifying a minimum time duration to the TKE algorithm
- Added the possibility of using the occupancy measure to the CEPN, CEPB and CorCEPB algorithms (thanks to Jiaxuan Li), an extension described in the Dawak 2019 paper.
- v 2.42- 2020-3-5 (4 new algorithms)
- New algorithm(s):
- the TKE algorithm for mining the top-k frequent episodes in a sequence of events (by Fournier-Viger et al.).
- the CEPB algorithm for mining low-cost high utility patterns (also known as cost-effective patterns) in a sequence database with cost and binary utility values (thanks to Jiaxuan Li)
- the CorCEPB algorithm for mining low-cost high utility patterns (also known as cost-effective patterns) in a sequence database with cost and binary utility values (thanks to Jiaxuan Li)
- the CEPN algorithm for mining low-cost high utility patterns (also known as cost-effective patterns) in a sequence database with cost and numeric utility values (thanks to Jiaxuan Li)
- Datasets
- Added some datasets with cost/utility sequences for discovering low-cost high utilty patterns (a.k.a. cost-efficient patterns).
- New algorithm(s):
- v 2.41- 2020-2-26 (6 new algorithms)
- New algorithm(s):
- the QCSP algorithm for mining the top-k quantive cohesive sequential patterns in a single sequence or in multiple sequences (thanks to Lens Fereman et al.)
- the MRCPPS algorithm for mining rare correlated periodic patterns common to multiple sequences (thanks to Peng Yang et al.)
- the HUE-SPAN algorithm for efficiently mining high-utility episodes in a sequence of events with utility information (thanks to Peng Yang et al.)
- the EMMA, MINEPI and MINEPI+ algorithms for mining frequent episodes in a sequence of events (thanks to Peng Yang et al.)
- Bug fix and documentation errors:
- Fixed a bug in ERMiner, was using == instead of equals() (thanks to Minh Pham for reporting the problem)
- Fixed various small problems in the online documentation and code of SPMF (thanks for Jiaxing Mai for reporting them)
- Datasets
- Re-organized the dataset page
- New algorithm(s):
- v 2.40- 2019-10-23 (9 new algorithms)
- New algorithm(s):
- the HUIM-ABC for mining high utility itemsets using Artificial Bee Colony Optimization (thanks to Wei Song and Chaoming Huang)
- the TKG algorithm for mining the top-k frequent subgraphs in a graph database (thanks to Fournier-Viger, P. and Chao Cheng)
- the gSpan algorithm for mining the frequent subgraphs in a graph database (thanks to Chao Cheng)
- the SPP-Growth algorithm for mining stable periodic itemsets in a transaction database (by Peng Yang)
- the MPFPS-BFS algorithm for mining periodic patterns common to multiple sequences (by Zhitian Li).
- the MPFPS-DFS algorithm for mining periodic patterns common to multiple sequences (by Zhitian Li).
- the NAFCP algorithm for mining frequent closed itemsets (thanks to Nader Aryabarzan et al.)
- the OPUS-Miner algorithm for mining self-sufficient itemsets (thanks to Xiang Li for converting the original C++ code to Java)
- Improvements to algorithm(s):
- Replaced the NegFin code with an improved version (thanks to Nader Aryabarzan et al.)
- Added an alternative and faster version of the MISApriori algorithm, named MISApriori(Srinivas) (thanks to Srinivas Paturu)
- New dataset(s):
- Added a new sequence database called ProofSequences to the dataset page of the SPMF website. It contains sequences of mathematical proof steps. Thanks to Nawas et al. for providing this dataset.
- Bug fix(es):
- Fixed a bug in the CHUI-Miner(Max) algorithm (thanks to Bao Vu for the bug fix)
- v 2.38 - 2019-02-02 (1 new algorithm)
- New algorithm(s):
- the PHM_irregular algorithm for mining irregular high utility itemsets. This algorithm is simply a variation of the PHM algorithm for the special case of finding irregular itemsets, which is equivalent to finding non periodic itemsets.
- New algorithm(s):
- the RPGrowth algorithm for mining rare patterns (thanks to Blake Johns and Ryan Benton for implementing the algorithm)
- New algorithm(s):
- v 2.37 - 2019-01-27 (4 new algorithm(s))
- New algorithm(s):
- the LHUI-Miner algorithm for discovering the local high utility itemsets from a transaction database with timestamps and utility information . Those are itemsets that have a high utility during some non predefined time intervals (thanks to Yimin Zhang et al. ).
- the PHUI-Miner algorithm for discovering the peak high utility itemsets from a transaction database with timestamps and utility information .Those are itemsets that have a utility that is much higher than usual (a peak) during some non predefined time intervals (thanks to Yimin Zhang et al.).
- the VHUQI algorithm for discovering quantitative high utility itemsets in a transaction database with utility information (modified and integrated from code under the GPL license from UP-Miner)
- the Occur algorithm for finding all occurrences of some sequential pattern(s) in sequences (by post-processing). This algorithm must be applied on the sequential patterns found by another sequential pattern mining algorithms such as CM-SPAM and PrefixSpan.
- Datasets:
- Added transactions datasets with timestamps to the dataset page, used for the LHUI-Miner and PHUI-Miner papers (prepared by Yimin Zhang)
- Bug fix:
- Fix a bug in GoKrimp such that the algorithm would not work with input files containing empty lines, and a bug related to the user interface when GoKrimp was runned without a label file (thanks to V�ctor Rodr�guez-Fern�ndez).
- Updated the CPT model so that it can now predict the next element of a sequence containing a single item.
- New algorithm(s):
- v 2.36 - 2019-01-08 (10 new algorithms)
- New algorithms:
- the CHUI-Miner(Max) algorithm for discovering maximal high utility itemsets in a transaction database with utility information
- the NegFIN and dFIN algorithms for frequent itemset mining (by Nader Aryabarzan et al. )
- the HUIF-PSO, HUIF-GA and HUIF-BA for mining high utility itemsets using particle swarm optimization, a genetic algorithm and a bat algorithm, respectively (by Wei Song, Chaomin Huang et al.)
- the PHUSPM and UHUSPM algorithms for discovering high utility probability sequential patterns in uncertain data (by Jerry Chun-Wei Lin, Ting Li et al.)
- the MEMU algorithm for mining high-average utility itemsets with multiple minimum average utility thresholds (by Jerry Chun-Wei Lin, Shifeng Ren et al.)
- the ProSecCo algorithm for progressive sequential pattern mining with convergence guarantees (thanks to Sacha Servan-Schreiber). This algorithm was runner-up for the best student paper award at ICDM 2018.
- Improvements:
- Improved the FHSAR implementation (thanks to Hoang Thi Dieu)
- New algorithms:
- v 2.35 - 2018-11-18 (1 new algorithm)
- New algorithms: the UFH algorithm for mining high utility itemsets (by Siddharth Dawar, Vikram Goyal et al.)
- v 2.34 - 2018-10-03 (5 new algorithms)
- New algorithms:
- Several algorithm implementations by Siddharth Dawar,
Vikram Goyal et al.:
- FHMDS algorithms for mining the top-k high utility itemsets in a data stream
- HMiner for high utility itemset mining
- UP-Hist for high utility itemset mining
- the DFI-Growth and LevelWise algorithms for recovering all frequent itemsets from frequent closed itemsets (thanks to _______)
- the Skopus algorithm for mining the top-k sequential patterns with leverage (obtained under GPL license)
- Several algorithm implementations by Siddharth Dawar,
Vikram Goyal et al.:
- Bug fix
- Fixed a bug in the MinFHM algorithm (thanks to Hung Nguyen for finding and fixing the bug)
- v. 2.33 - 2018-06-10 (new features)
-
New features
- I have added the possibility of displaying the sequences IDs for patterns output by the Fournier-Viger08, SeqDim, TopSeqRules, TopSeqClassRules, and TNS algorithms. In the GUI of SPMF, this feature is used by setting the optional "Show sequence ids?" parameter to true.
- I have added the possibility of displaying the transactions IDs for patterns output by the TopKRules, TopKClassRules and TNRalgorithms. In the GUI of SPMF, this feature is used by setting the optional "Show transaction ids?" parameter to true.
- I have added a new algorithm called "Closed_class_association_rules(using_fpclose)" to mine class association rules with a single item in the consequence. I have not updated the documentation for this algorithm yet.
- v. 2.31 / 2.32 - 2018-03-31 / 2018-04-02 (bug
fix)
-
New algorithms
- The HUIM-GA and HUIM-BPSO, HUIM-GA-tree and HUIM-BPSO-tree algorithms have been reintroduced in SPMF. They had previously been removed due to bugs in the Java conversion of the original C++ code. The problem was that the code was translated from C++ but the memory management model is different in Java and there was some deep copy problem, principaly. The bugs of the Java implementation have been fixed by Chaomin Huang.
- v. 2.30c - 2018-03-10 (new feature)
-
New algorithms
- Fixed a bug in FPGrowth in the "saveAllCombinationsOfPrefixPath" function such that the support of some itemsets was incorrectly calculated (thanks to Konstantin B�ttcher for reporting the bug)
- v. 2.30 - 2018-03-10 (new feature)
-
New algorithms
- Added a feature to show the names of items in results when using some sequential pattern mining algorithms with the user interface or command line of SPMF (the documentation will soon be updated to explain this feature in more details).
- v. 2.29 - 2018-02-16 (1 new algorithm)
-
New algorithms
- Replaced the FCHM algorithm by a newer implementation called FCHM_bond for mining correlated high utility itemsets using the bond measure, and added the new FCHM_allconfidence algorithm for discovering correlated high utility itemsets using the all-confidence measure. (implemented by Yimin Zhang).
- Removed features :
- I temporarily removed the HUIM-GA and HUIM-BPSO algorithms from the website because the Java implementations of these algorithms have been reported to have a bug. The original implementation were written in C++. It seems that there was some error in the conversion process from C++ to Java. When the bugs are fixed, these algorithms will be added again to SPMF.
- v. 2.29 - 2018-02-16 (2 new algorithms)
-
New algorithms
- Added the original implementations of the FAST and CloFAST algorithm for sequential pattern mining (thanks to Fabio Fumarola, Pasqua Fabiana Lanotte, Michelangelo Ceci, Donato Malerba, Eliana Salvemini, Jiawei Han for contributing the original source code).
- v. 2.28 - 2018-02-10 (2 new algorithms)
-
New algorithms
- Added an algorithm named TopKClassRules, which is a variation of TopKRules that allows to discover the top-k class association rules, that is the k most frequent association rules that appear in a dataset, where the consequent of rules is an item chosen from a list of allowed items specified by the user.
- Added an algorithm named TopSeqClassRules, which is a variation of TopSeqRules that allows to discover the top-k class sequential rules, that is the k most frequent sequential rules that appear in a sequence database, where the consequent of rules is an item chosen from a list of allowed items specified by the user.
- v. 2.27 - 2018-02-05
-
New features
- Added an optional maximum pattern length parameter
to several algorithms: HMine, defMe,
AlgoAprioriTID_Bitset, AprioriTID, CORI, Eclat, Eclat_bitset,
dEclat, dEclat_bitset, MSApriori, Pascal, UApriori, VME, LCMFreq,
The documentation for these new parameters has not been updated yet but they can be used in the user interface and source code..
- Added optional maximum antecedent and maximum
consequent parameters for several algorithms: CMDeo,
CMRules, ERMiner, TopSeqRules, TNS, TopKRules, TNR
The documentation for these new parameters has not been updated yet but they can be used in the user interface and source code.
- Added an optional maximum pattern length parameter
to several algorithms: HMine, defMe,
AlgoAprioriTID_Bitset, AprioriTID, CORI, Eclat, Eclat_bitset,
dEclat, dEclat_bitset, MSApriori, Pascal, UApriori, VME, LCMFreq,
- v. 2.26 - 2018-02-02 4 new algorithm(s))
-
New algorithm(s)
- Added a tool to calculate statistics about a transaction database with utility information.
- Added the original implementation of the CHUD algorithm for closed high utility itemset mining and the TKU algorithm for top-k high utility itemset mining (from UP-Miner under the GPL license)
- Added a simple implementation of the TKO-Basic algorithm for mining the top-k high utility itemset mining. Note that this implementation does not include all the optimizations of TKO described in the journal paper. But this implementation can still be quite fast.
- v. 2.25 - 2018-01-29 (1 new algorithm)
-
New algorithm
- Algorithm to calculate the median smoothing of a time series.
- v. 2.24 - 2018-01-25 (bug fixes)
- Bug fixes
- Fixed some bugs in the TDAG and LZ78 sequence prediction models to improve their performance, and fix other related issues (thanks to Luis Angerstein and Jan Wolter for providing these improvements).
- Remove some unused variable and condition in FPGrowth (thanks to Konstantin B�ttcher for reporting the problem)
- Modified TS-HOUN so that a clearer error message is shown to the user when the parameter "period count" is incorrectly set (thanks to C. Sivamathi for reporting the problem)
- Bug fixes
- v. 2.23 - 2018-01-21 (new algorithms)
- New algorithm(s):
- The TUP algorithm to discover the top-k high utility episodes in a complex event sequence (thanks to Sonam Rathore, Siddarth Dawar et al for providing their original implementation.)
- The UP-SPAN algorithm to mine high utility episodes in a complex event sequence (from UP-Miner under the GPL license)
- New algorithm(s):
- v. 2.22 - 2018-01-07 (bug fix + 1 new algorithm)
- Added some new algorithm(s):
- The EHAUPM algorithm to discover high average utility itemsets (thanks to Jerry Chun-Wei Lin, Shi-feng Ren et al.)
- Bug fixe(s):
- Fixed a bug in the output of HAUI-Miner such that the average utility was always rounded to an integer value.
- Added some new algorithm(s):
- v. 2.21 - 2018-01-01 (bug fixes + 9 new algorithms)
- Added some new algorithm(s) related to time series analysis:
- Algorithm to calculate the min max normalization of a time series.
- Algorithm to calculate the standardization of a time series.
- Algorithm to calculate the first order differencing of a time series
- Algorithm to calculate the second order differencing of a time series
- Algorithm to calculate the exponential smoothing of a time series
- Algorithm to calculate the autocorrelation function of a time series
- Algorithms to calculate the prior average, central average and cumulative average of a time series (previously, only the prior average was available in SPMF and was called "moving average". Now three types of moving average are offered and the prior moving average has been renamed)
- Bug fixe(s):
- Fixed a bug in AlgoArrays.java that could cause incorrect results by the TNR algorithm (thanks to Rashmie Abeysinghe for reporting the bug).
- Bug fixe(s):
- Fixed a bug such that the optional sequence identifiers in the output of some sequential pattern mining algorithms were incorrect. According to the documentation, sequence identifiers should start at 0, while for some algorithms, the sequence identifiers were starting from 1. Now the sequence identifiers start from 0 for all the algorithms. Thanks to Mathieu Gousseff for reporting the bug.
- Fixed a bug in the USpan algorithm such that the SWU upper-bound was looser than it should (thanks to Tin Truong Chi for finding and fixing the bug).
- Fixed a bug for the FEAT algorithm such that it was throwing exception when using the optional parameter to show sequence identifiers..
- Added some new algorithm(s) related to time series analysis:
- v. 2.19 - 2017-10-22 (4 new algorithms)
- New algorihtm(s):
- An algorithm to calculate the regression line of a time series using the least squares method. After applying the algorithm to train a linear regression model, the model.can be used to make some simple predictions.
- The mHUIMiner algorithm for high utility itemset mining (by Peng et al. from GitHub, GPL license)
- The ULB-Miner algorithm for high utility itemset mining (by Duong, H, Fournier-Viger et al.)
- New feature(s):
- Added an implementation of FHM called FHM(float) which can take utility values as float values instead of integers.
- Added the possibility of specifying a maximum pattern length to the following algorithms : Apriori, AprioriHT, FPGrowth, FPGrowth_association_rules, FPGrowth_association_rules_with_lift
- For sequence prediction, the Evaluator class was modified so that the SPMF format is used to compare sequence prediction models instead of another format.
- Bug fixe(s):
- Fixed a bug in the new version of the Apriori implementation with length constraint. Thanks to Muhammad Yasir Chaudhry for reporting the bug.
- Fixed a bug in the HUIM-BSO, HUIM-BSPtree algorithms in terms of supported input file format. Thanks to Majdi Mafarja for reporting the problem.
- Fixed a bug in the output format of PrefixSpan and BIDE+ algorithms (some -1 were missing in some cases). Thanks to Matthieu Gousseff for reporting the bug.
- Improved the documentation of SPMF by dividing the single documentation page into multiple webpages (for achival purpose, the old documentation page for SPMF 2.18 can be found here).
- New algorihtm(s):
- v. 2.18 - 2017-08-06 (new versions of two algorithms, fix bug,
fix dataset issue)
- Added two new versions of the AprioriRare and AprioriInverse algorithms called "AprioriRare_TID" and "AprioriInverse_TID". These versions are based on AprioriTID instead of the regular Apriori. They thus keep transactions identifiers of patterns in memory to avoid scanning the database repeatedly, and can output the transaction ids to the output file (by setting the parameter "Show transactions IDs? to true in the user interface).
- Fixed and reuploaded the "retail" and "pumsb" datasets. They contained an item with the id "0". But some algorithms such as EFIM assume that item identifiers must be positive (thanks to Srikumar Krishnamoorthy for reporting this problem)
- Added a tool to add a value to all item identifiers in a transaction database. This was used to fix the above dataset problem.
- Fixed a bug in the generation of closed association rule mining using the FPClose algorithm (thanks to Benjamin Andow for reporting the bug)
- v. 2.17 - 2017-07-03
- Added optional parameters for the PFPM and PHM algorithms to specify the minimum and maximum number of items that patterns should contain.
- Modified the user interface so that algorithms can have up to seven parameters.
- v. 2.16
- Added a new feature to the CPT and CPT+ sequence prediction models. The user can now obtain information about how a prediction was made. By using the method getCountTable, one can obtain all the symbols and their scores calculated by the model. This explains what is the basis for a given prediction.
- v. 2.15 (4 new algorithms)
- Added implementation of four algorithms (by Jerry
Chun-Wei Lin, Ting Li, et al.)
- the FFI-Miner algorithm for mining fuzzy frequent itemsets in a quantitative transaction database (similar to a database with utility values)
- the MMFI-Miner algorithm for mining fuzzy frequent itemsets in a quantitative transaction database
- the HAUI-Miner algorithm for mining high average utility itemsets in a transaction database with utility values.
- the HAUI-MMAU algorithm for mining high average utility itemsets in a transaction database with utility values using multiple minimum average-utility thresholds.
- Added implementation of four algorithms (by Jerry
Chun-Wei Lin, Ting Li, et al.)
- v. 2.14 (bug fix)
- Fixed a bug the USpan implementation such that some patterns could be missed (thanks to Tai Dinh and Tin Truong Chi for reporting the bug).
- v. 2.13 (bug fix)
- Fixed a bug in Closed association rule mining with FPClose. Some exception was thrown in some rare case (thanks to Tarannum Zaman).
- v. 2.12 - 2017-02-05
- Added a new optional parameter to several itemset mining algorithms to let the user decide whether transactions identifiers should be shown in the output file, for each pattern found. The algorithms that support this feature are: AprioriTID, AprioriTID_bitset, Apriori_TIDClose, Charm_bitset, Charm_MFI, Eclat, Eclat_bitset, DCI_closed, CORI. In the user interface of SPMF, the new optional parameter is displayed as "Show transactions IDs? (optional)".
- v. 2.11 - 2017-01-27 (5 new algorithms)
- Five new algorithms for high-utility itemset mining have been
added (by Jerry Chun-Wei Lin, Lu Yang, Philippe
Fournier-Viger)
- SFUPMinerUgmax for mining skyline frequent-utility patterns
- HUIM-GA and HUIM-GA-tree algorithms for mining high-utility itemsets using genetic algorithms
- HUIM-BPSO and HUIM-BPSO-tree algorithms for mining high-utility itemsets using particle-swarm optimization
- Five new algorithms for high-utility itemset mining have been
added (by Jerry Chun-Wei Lin, Lu Yang, Philippe
Fournier-Viger)
- v. 2.10 - 2017-01-17
- The SAX algorithm has now a new optional parameter "deactivatePAA". It allows to deactivate the transformation to the piecewise aggregate approximation (PAA) when applying SAX. This allows to convert a files containing several time series having different lengths to their SAX representations while preserving their original lengths (rather than converting all of them to time series having the same length).
- Fixed a bug in the TopKRules algorithm that was introduced in a previous version of SPMF. The output was correct but the algorithm was not using the set "candidates" in the most efficient way. (Thanks to Bima Haryanto Putra for reporting the bug)
- Fixed a bug in the MaxSP algorithm (thanks to Natalia Mord for proposing the bug fix).
- v. 2.09 - 2016-12-28
- Added a vizualization tool called the Instance viewer for visualizing the input files of clustering algorithms such as K-Means and DBScan
- Improved the documentation of the clustering algorithms with some more interesting examples and pictures. Moreover, also did some minor improvements to the code of clustering algorithms. In particular, the input file format for clustering algorithms now let the user specify the names of attributes used to describe the instances.
- I have also improved the Cluster Viewer to let the user select which attributes should be visualized when displaying clusters. Thus the Cluster Viewer can now be used to visualize instances having more than 2 attributes.
- Fixed a bug in the user/interface and command line interface of SPMF for the parameter "required items" of the TKS algorithm.
- v. 2.08 - 2016-12-25 (cluster visualization)
- Added a vizualization tool called the Cluster Viewer for visualizing clusters of 2D points found by clustering algorithms such as K-Means and DBScan
- Moved the TimeSeries viewer to another package and added a few additional features to its user interface..
- v. 2.07 - 2016-12-21
- Modified the clustering algorithms (K-Means, Bisecting K-means,
Hierarchical clustering, DBScan and OPTICS) such that:
- a label (a name) can be assigned to each instance in the input file. The names of instances are now displayed in the output of these algorithms. This provides more meaningful results.
- a separator such as " " can be provided as parameter to these algorithms. The separator indicates which character is used in the input file to separate values. As a result, most clustering algorithms are now compatible with the time series file format and can be applied to time series (when using the ',' separator).
- Fixed a bug when running the OPTICS algorithm in the user interface or command line interface of SPMF.
- Minor improvements to the Time Series Viewer. When the user moves the mouse over a time series, the name of the time series is shown. Also other minor changes.
- Modified the clustering algorithms (K-Means, Bisecting K-means,
Hierarchical clustering, DBScan and OPTICS) such that:
- v. 2.06 - 2016-12-18 (time-series mining)
- Added support for time-series data mining
- an implementation of the SAX algorithm is provided for converting time series to sequence(s) of symbols. This is useful to then apply traditional sequential pattern mining algorithms or sequential rule mining algorithms to time series.
- an algorithm to calculate the moving average of a time-series (this is useful for making a time series appears more "smooth" by removing noise)
- an algorithm to calculate the piecewise-aggregate approximation of a time-series, which is used to reduce the dimensionality of a time-series
- an algorithm to split a time-series into a given number of time series, or by number of data points.
- a vizualization tool called TimeSeriesViewer for visualizing time-series.
- Fixed an encoding bug for the conversion of chinese texts to sequences such that chinese characters were not appearing.
- Fixed a bug related to the command line interface of SPMF
- Updated the developer's guide on the website with some minor modifications.
- Added support for time-series data mining
- v. 2.05 - 2016-11-16
- Fixed a bug in the command line interface (thanks to Andrey Shestakov for reporting the bug)
- v.2.04- 2016-10-14
- Improved the graphical user interface and command line interface of SPMF so that more informative messages are shown to the user when an algorithm parameter is missing or when the value is of an incorrect type. This will make the user interface more user-friendly (thanks to Slimane Oulad Naoui for this suggestion).
- v.2.03- 2016-10-13
- Fixed a bug in the VMSP algorithm (AlgoVMSP.java) such that some patterns were missing in some cases when the maxgap constraint was used (thanks to Antoine Pigeau for reporting the problem)
- v.2.02- 2016-10-12
- Added support for mining TEXT files with Chinese text (by supporting the Chinese punctuation).
- Fixed a bug in the FOSHU and TSHOUN algorithms, an updated the documentation and sample input file for these algorithms (thanks to Yimin Zhang for reporting the problem)
- v.2.01 - 2016-09-16 (several improvements)
- Added the support for TEXT files. Using the graphical interface or command line, it is now possible to apply most sequential pattern mining and sequential rule mining algorithms directly to a text file. There is two ways of applying an algorithm on a text file. The first way is to apply the algorithm "Convert_TEXT_file_to_sequence_database" to transform a text file into a sequence database. Then this file can be used with most algorithms for sequential pattern or rule mining using the user interface or command line. The second way is to rename the text file with the extension ".text". Then when using the graphical interface or command line, SPMF will automatically convert the file to the SPMF format, run the selected algorithm, and then show the results in terms of words in the text file rather than integers. This is a feature that has been requested by several users. It is useful for performing data mining on text files without having to write code for converting text to sequences as it was previously required. For now, SPMF only supports the default text file encoding supported by Java. In the future, some options will be added to let the user choose other encodings as well. There is a new example in the documentation that provides also some explanations about how to use text files when running algorithms using the source code version of SPMF. Moreover, a tutorial on the blog explains some of the possibilities for analyzing text documents using this new version of SPMF.
- A new system has been designed for adding new algorithms to SPMF. To add an algorithm, an instance of the class DescriptionOfAlgorithm must be created for the new algorithm in the package "ca.pfv.spmf.algorithmmanager.descriptions". It allows to indicate the type of input, output, the parameters, etc. of the algorithm. This is then used to automatically generate the list of algorithms in the user interface of SPMF, unlike in previous versions of SPMF where this list was hard-coded. In the future, the descriptions of algorithms could be used to build a more complex user interface where user could visually combine various algorithms as a workflow. Another interesting possibility is to provide a user interface to run multiple algorithms one after the other, or to launch experiments where the parameters are varied automatically. This will be considered for features in future releases of SPMF. Moreover, another idea is to use the algorithm descriptions for adding a plug-in system in SPMF for importing algorithms from other jar files. In the next few days, I will also update the developper's guide to add more documentation.
- Added the lift measure to the CMDeo algorithm (thanks to Ryan Panos).
- Updated the code of the GCD algorithm for association rule mining with an improved version (thanks to Ahmed El-Serafy, Hazem El-Raffiee).
- Fixed some minor errors in the documentation.
- Fixed a bug in the CMDeo algorithm that could trigger an ArrayOutOfBoundException .
- Fixed a bug in the Pascal implementation (the support of single items was incorrect in some cases).
- Fixed a bug in the user interface for the FP-Close algorithm.
- Fixed a bug in the VMSP and VGEN algorithms that occurred when maxLength was set to 1.
- v.0.99j - 2016-06-16
- Fixed a bug in the VMSP implementation (thanks to Himel Dev for reporting the bug)
- Two additional large itemset mining datasets have been added to the datasets page of the website: PowerC and Susy (thanks to Zhang Zhongjie)
- v.0.99i - 2016-06-09 (1 new algorithm)
- Added an implementation of the GCD algorithm for mining association rules (thanks to Ahmed El-Serafy, Hazem El-Raffiee for providing the implementation)
- v.0.99h - 2016-06-09
- Added a tool to resize databases in SPMF format using a percentage of lines from an original database (useful for performing scalability experiments)
- Fixed a bug in the FHSAR implementation (thanks to Gehad Ahmed Soltan Abd-Elaleem for reporting the bug)
- v.0.99g - 2016-06-02 (4 new algorithms)
- Added an implementation of the MinFHM algorithm for mining minimal high-utility itemsets.
- Added an implementation of the PFPM algorithm for mining frequent periodic patterns in a transaction database (a sequence of transactions)
- Added an implementation of the PHM algorithm for mining periodic patterns that have a high utility (e.g. yield a high profit) in a sequence of transactions (a transaction database)
- Added an implementation of the SkyMine algorithm for mining skyline high-utility itemsets (thanks to V. Goyal. et al.)
- Added a tool to remove utility information from transactions databases containing utility information.
- v.0.99f - 2016-05-30
- Fixed a bug that may generate incorrect support count in VMSP and other SPAM based algorithms in some specific cases. The bug was introduced in a previous version when adding the maxgap constraint to SPAM based algorithms (thanks to Preethy Varma for reporting the bug)
- Seven large datasets for itemset mining have been added to the datasets page of the website: kddcup99, Skin, Pamp, USCensus, OnlineRetail, and RecordLink (thanks to Zhang Zhongjie)
- v0.99e - 2016-03-29 (1 new algorithm)
- Added the original implementation of the EFIM-Closed algorithm for mining closed high-utility itemsets.
- v0.99d - 2016-03-23 (1 new algorithm)
- Added the original implementation of the FHM+ algorithm for efficiently mining high-utility itemsets with length constraints.
- v0.99c - 2016-03-13
- Fixed bugs in the new BIDE+ and PrefixSpan implementation that occurred for sequences containing multiple items per itemset.
- v0.99b - 2016-02-28
- I have further optimized the new Prefixspan implementation, in the package ca.pfv.spmf.algorithms.sequentialpatterns.prefixspan.
- I have replaced the old implementation of BIDE+ with a new implementation. The new implementation is in the package ca.pfv.spmf.algorithms.sequentialpatterns.prefixspan. This new implementation is faster and more memory efficient (up to 10 times faster on some dataset, and uses less memory). I have tested this implementation quite well. But if you find some issues, please let me know. Note that some algorithms may still rely on the old implementation (e.g. the Fournier08 algorithm). I will further clean the code in upcoming versions of SPMF to avoid keeping two versions of BIDE+.
- Fixed a bug in the FOSHU and TS-HOUN algorithms. The absolute value of to(X) is now used to calculate the relative utility of an itemset X.
- v0.99 - 2016-02-21
- In this new version, I have replaced the Prefixspan implementation with a new implementation, in the package ca.pfv.spmf.algorithms.sequentialpatterns.prefixspan. This is something that I have wanted to do for a while since the previous version had been implemented a long time ago. The new version is based on different design decisions and includes some additional optimizations. It can thus be more than 10 times faster than the previous implementation on some dataset and use three times less memory. This also makes the RuleGen algorithm faster since it relies on PrefixSpan. Note that some algorithms may still rely on the old implementation.
- v0.98e - 2016-02-05
- Added the possibility to mine closed association rules using FPClose. The version using FPClose can be 10 times faster than the version using Charm for the step of rule generation because FPClose stores closed itemsets in a CFI-tree.
- v0.98d - 2016-02-02
- Fixed a bug in DBScan, Optics, and the KD-Tree implementation.
- v0.98c - 2016-01-29 (1 new algorithm):
- Added an implementation of the USPAN algorithm for mining high-utility sequential patterns.
- v0.98b - 2016-01-28 (1 new algorithm):
- Added an implementation of the FCHM algorithm for mining correlated high-utility itemsets using the bond measure.
- Modified the output of TKS to remove the -2 at the end of each pattern found, so that the output is similar to other sequential pattern mining algorithms.
- v0.98 - 2016-01-14 (added a new window for
result visualization)
- This new version offers a new user user interface for vizualizing results. It is a window specifically designed for visualizing patterns found by pattern mining algorithms but it works with clustering algorithms and most algorithms. This window can be accessed when using the graphical interface of SPMF by selecting the checkbox "using SPMF viewer". The new window show the patterns found by an algorithm in a table, and it let the user apply some filters to select patterns or to sort the patterns by ascending or descending orders using various measures such as support and confidence (depending on the algorithms) by clicking on the column headers. This window for visualizing patterns should work with most algorithms offered in SPMF. If you find some bugs related to this new window for visualizing results, or if you have ideas to improve the user interface of SPMF, you may let me know.
- Besides, I fixed a few bugs.
- v0.97d / 0.97e - 2015-12-06 (2 new
algorithm)
- Added an implementation of the GHUI-Miner algorithm for mining generators of high-utility itemsets in a transaction database having utility information.
- Added an implementation of the CHUI-Miner algorithm for mining closed high-utility itemsets in a transaction database having utility information.
- Fixed a bug in MaxSP. No result where generated for minsup = 0 sequence. Now, if the user set minsup = 0 sequence, MaxSP change minsup to 1 sequence (because it does not make sense to generate patterns that do not exist in the database).
- Fixed a bug in FPClose (thanks to Jamshi Nazeer for reporting the bug)
- Fixed a bug in the GoKrimp algorithm when reading a file without optional labels (thanks to Jaroslav Fowkes and Thomas Christie for reporting the bug)
- Fixed a bug in the ClaSP / CMClasp algorithms when handling
databases with multiple items per itemsets (thanks to Tin Truong Chi for the bug
fix)
- v0.97c - 2015-10-28 (1 new algorithm)
- Added a variation of the FHM algorithm named FHMFreq for mining frequent high-utility itemsets. This is a quite simple modification of FHM to add the minsup threshold.
- v0.97b - 2015-10-06 (1 new algorithm)
- Added an implementation of a Naive Bayes Document Classifier (implemented by Sabarish Raghu)
- Fixed a bug in the text clusterer (bug reported and fixed by Dharmen Punjani)
- Fixed a bug in FPClose (thanks to Insil Yun)
- v0.97a - 2015-09-19
- Fixed a bug in the graphical interface for the SPAM algorithm (thanks to Martin B�ckle for reporting the bug).
- Added the minimum pattern length constraint for the SPAM algorithm.
- v0.97 - 2015-09-12 (major revision - 16 new
algorithms)
- Added several sequence prediction algorithms to SPMF.
The algorithms are CPT+, CPT, PPM, DG, AKOM, TDAG and LZ78. Those algorithms are designed to predict the next symbol of a given sequence based on a set of training sequences. The algorithms are implemented by Ted Gueniche, as part of its Ipredict project. - Added an implementations of FOSHU and TS-HOUN for on-shelf high-utility itemset mining.
- Added an implementations of EIHI and HUI-LIST-INS for incremental high-utility itemset mining.
- Added an implementation of HUSRM for high-utility sequential rule mining.
- Added an implementation of EFIM, d2HUP and HUP-Miner algorithms for high-utility itemset mining.
- Added an implementation of HUG-Miner for mining high-utility generator patterns
- Added more performance comparisons on the "Performance" page of the website
- Added datasets for on-shelf utility mining and high utility sequential rule mining on the "Datasets" page of the website.
- Fixed a bug in the "maxgap" constraint implementation for the TKS, CM-SPAM algorithms and other SPAM based algorithms, that sometimes occured when an item appeared multiple times in the same sequence.
- Updated the map of data mining algorithms.
- This version requires to have Java 1.8, installed on your machine. It may be necessary to update the Java SDK on your machine and perhaps also your development environment such as Eclipse.
- Added several sequence prediction algorithms to SPMF.
- v0.96r20 - 2015-08-25
- Added an optional parameter to SPAM, VMSP, VGEN and TKS to show the identifiers of sequences containing each pattern found. If this parameter is set to true, the identifiers of sequences will be shown in the output by these algorithms.
- v0.96r19 - 2015-08-18
- Fixed a bug in the FPGrowth algorithm that was introduced in v96r14 when some optimizations where made to the FPGrowth code (thanks to Masanori Akiyoshi for finding the bug). The support of itemsets was in some cases incorrectly calculated.
- Fixed an integer overflow problem occuring only for very large datasets for FHM, FHN and HUI-Miner.
- Fixed a bug in the CORI algorithm (thanks to Pierre-Emmanuel Leroy)
- v0.96r17/r18 - 2015-05-26
- Further optimization of memory usage for the Eclat, dEclat, Cori and DefMe algorithms.
- Fixed a bug in the correlation distance function for clustering.
- Fixed a bug that occurred when using the "maxgap" constraint in the VMSP, VGEN, CM-SPAM, SPAM and TKS algorithms (thanks to Choong Shin Siang and Wong Li Pei for reporting the bug).
- Optimized the H-Mine algorithm implementation.
- Fixed a bug in FHN.
- Fixed a bug in the UPGrowth+ implementation (thanks to Prashant Barhate for contributing this implementation)
- v0.96r16 - 2015-04-28 (1 new algorithm)
- Added an implementation of the CORI algorithm for mining rare correlated itemsets from a transaction database.
- Added an implementation of the FPClose algorithm for mining closed frequent itemsets from a transaction database.
- Added an implementation of the PrePost+ algorithm (a variation of PrePost) for frequent itemset mining
- Added an implementation of the FHN and HUINIV-Mine algorithms for high-utility itemset mining with negative or positive unit profit values.
- v0.96r14 - 2015-04-05 (1 new algorithm)
- Added an implementation of the FPMax algorithm for mining maximal frequent itemsets from a transaction database.
- Fixed a bug in the dCharm_bitset implementation. The result was sometimes incorrect.
- The runAlgorithm() method of CommandProcessor is now public as requested by some user.
- v0.96r13 - 2015-03-22 (1 new algorithm)
- Added an implementation of the Optics algorithm. Optics generates a cluster-ordering from a set of double vectors. From this ordering, various things can be done. I have implemented the method extractDBScan() method to use this ordering to generate DBScan style clusters. I have however not implemented the alternative extractCluster() method, described in the paper.
- v0.96r12 - 2015-03-21
- Fixed a bug in the hash function of CloSpan, ClaSP and CM-ClaSP, that provoked a StackOverflow exception for these algorithms in some rare cases (thanks to Wen Zhang for reporting the bug and Antonio Gomariz for fixing it).
- v0.96r11 - 2015-03-16
- Fixed a bug in the Zart algorithm (reported by Asmaa) that was generating an ArrayOutOfBound exception when no single items were frequent. Furthermore, I have modified the outpout of Zart to make it clearer and updated the documentation.
- v0.96r10 - 2015-03-12
- Modified the graphical user interface of SPMF (files in the package ca.pfv.spmf.gui) so that when the user is launching an algorithm, it is now done in a separated thread and a button "Stop algorithm" is available to stop the algorithm execution if it is taking too much time.
- v0.96r9 - 2015-03-07 (1 new algorithm)
- Added an implementation of the DBScan algorithm for density-based clustering.
- Added the feature of searching all points within a radius to the KD-Tree implementation.
- v0.96r8 - 2015-03-05
-
New feature for most sequential pattern mining algorithms: the user
can now request to show the corresponding sequence ids for each
pattern found. In other words, for each pattern found, SPMF can now
show the ids of the sequences where the pattern appears. This feature
was added in BIDE+, ClaSP, CM-ClaSP, CloSpan, CM-SPADE, CM-SPAM,
SPADE, SPAM-AGP, GSP, PrefixSpan, TSP, MaxSP, FEAT and FSGP. The
documentation will be updated soon... Moreover, I fixed some minor
issues in the code of FEAT and FSGP (the code for saving to file was
not working as expected for these algorithms).
- v0.96r7 - 2015-02-17 (1 new algorithm)
- Added an implementation of the Bisecting K-Means clustering algorithm.
- Added more features to the K-Means and Hierarchical Clustering algorithms. Previously, the euclidian distance was the only distance function available. Now, the user can choose between Euclidian distance, correlation distance, cosine distance, Manathan distance and Jaccard distance.
- Update: 2015-02-19: Fixed a bug in the command line interface of SPMF (bug reported by Wen Zhang).
- v0.96r6 - 2015-02-16
- Fixed bugs in the dEclat, dCharm algorithms and FIN/PrePost implementations.
- v0.96r5 - 2015-02-13
- Added the "max gap" parameter for the VGEN, VMSP, TKS, SPAM, SPAM and CM-SPAM sequential pattern mining algorithms. It is an optional parameter that allows to specify if gaps are allowed in sequential patterns. For example, if "max gap" is set to 1, no gap is allowed (i.e. each consecutive itemset of a pattern must appear consecutively in a sequence). If "max gap" is set to N, a gap of N-1 itemsets is allowed between two consecutive itemsets of a pattern. If the parameter is not used, by default "max gap" is set to +∞.
- Fixed a bug in the Itemset-Tree and Memory Efficient Itemset-Tree implementations (thanks to Ryan G. Benton for reporting and fixing the bug). The support of itemsets was sometimes calculated incorrectly.
- v0.96r3/r4 - 2015-02-05 (3 new algorithms)
- Added an implementation of a Text Clusterer using the tf*idf measure (thanks to Sabarish Raghu)
- Added an implementation of the EstDec+ algorithm, for mining recent frequent itemsets from data streams (thanks to Azadeh Soltani).
- Memory optimizations of the EstDec algorithm. The algorithm can now use up to 4 times less memory (thanks to Azadeh Soltani).
- Memory optimization of the FPGrowth algorithm to reduce the number of object creation. Reduces memory usage by up to 2 times on some datasets. Also optimized how FPGrowth enumerate all itemsets when an FP-Tree contains a single branch.
- Refactoring of classes in the package ca.pfv.spmf.gui to separate the main class file and command line interface (Main) from the graphical interface (MainWindow) and from the code for launching algorithms (CommandProcessor) used by both the command line interface and GUI. From now on, the class "Main" will be the main class of the SPMF library.
- Refactoring of the CM-ClaSP and ClaSP code so that the debuging code for showing the trie is now located in a separated class (ShowTrie). This is to avoid HeadlessExceptions when running ClaSP/CM-ClaSP in a headless environment (bug reported by Wen Zhang), that is an environment where graphical interface is available (e.g. on some Linux servers).
- Fixed a bug in BIDE+ that was causing ArrayOutOfBound exception on some datasets (thanks to Mehran Memon for reporting this bug).
- Other minor modifications to remove some warnings.
- Fixed a bug in dEclat implementations. Due to an error in how methods were overloaded, some code of Eclat was executed in dEclat.
- Fixed a bug. MaxSP was not working when executed from the GUI.
- Fixed a bug about how an ID3 decision tree was printed to console (thanks to G. Gutierrez for reporting this bug)
- Optimization: replaced StringBuffer by StringBuilder in all classes (since it is more efficient).
- Added the BMS2 dataset to the "dataset" page of the website.
- Added more features to the CM-SPAM algorithm
- allow the user to specify items that need to appear in patterns found.
- allow the user to specify the minimum/maximum length of patterns to be found.
- Added more features to the RuleGrowth/TRulegrowth algorithms. User can now specify the maximum size of rule antecedents/consequents to be found.
- v0.96r2 - 2014-11-30
- Added more features to the TKS algorithm for top-k sequential
pattern mining
- modified TKS to allows the user to specify items that need to appear in patterns found.
- modified TKS to allows the user to specify the minimum length of patterns to be found.
- Added the "fix transaction database" tool. It is a tool that fix some common problems that may be found in transaction database files created by users. This tool (1) removes duplicate items in transactions of a transaction database and (2) sort items in transactions (those requirements are assumed by most itemset mining algorithms).
- Added more features to the TKS algorithm for top-k sequential
pattern mining
- v0.96r - 2014-11-24 (4 new algorithms)
- Added the FIN and PREPOST algorithms (thanks to Zhihong Deng for providing the original C++ source code, that I have converted to Java). These two algorithms are very recent frequent itemset mining algorithm and are very fast. According to some preliminary experiments, for example, PrePost can be a few times faster than FPGrowth on some datasets.
- Added implementations of the LCMFreq, LCM and LCMMax algorithms for respectively mining frequent itemsets, closed itemsets and maximal itemsets (thanks to Alan Souza for providing an implementation of LCM). I have modified the source code to add a few optimizations. The implementation of LCM is based on the paper describing LCM v.2 by Uno, although it does not perform transaction merging yet (some more optimizations could be added in the future). LCM is an interesting algorithm because it was the winner of the FIMI 2004 competition.
- Update (2014-11-24): There was a bug in my modifications of LCM to implement LCMMax, so LCMMax is temporarilly removed from the source code until I can fix the issue. It may takes a few days or more before I can fix it.
- v0.96q - 2014-09-25
- Fixed a bug in the compare() method of the Rule class used by TNS and TopSeqRules (thanks to C. Albert Thompson for reporting the bug).
- New tools:
- Added a tool to add consecutive timestamps to a sequence database (this is useful for generating datasets with timestamps for testing algorithms that require timestamps).
- Added a tool for converting a transaction database to a sequence database (this can be useful for generating datasets for experiments, though in real-life, it may not make sense to convert transactions without ordering to sequences with an ordering).
- Added a tool to add synthetic utility values to a transaction database (this is useful for generating datasets to be used in high utility itemset mining).
- v0.96p- 2014-09-14 (3 new algorithms)
- Added an implementation of the ERMINER algorithm for sequential rule mining.
- Added an implementation of the IHUP and UP-GROWTH algorithms for high-utility itemset mining (thanks to Prashant Barhate for implementing these algorithms).
- v0.96o- 2014-09-12
- Fixed a bug in Eclat so that frequent itemsets found where not correctly separated by their size and another bug in Eclat such that Eclat was not pruning some itemsets containing 2 items when the triangular matrix was deactivated. (thanks to Abdalghani Abujabal).
- Fixed a bug that occured when running the "Fournier08-Closed+time" algorithm using the GUI, (thanks to Nahumi)
- v0.96n- 2014-08-15
- Added a tool to convert a sequence database to a transaction database. This tool is useful for example to apply an algorithm designed for a transaction database to a sequence database (e.g. mining association rules in a sequence database).
- Added a tool to generate statistics about a transaction database.
- Fixed a bug in the association rule generation using CFPgrowth that was introduced in a previous version.
- v0.96j- 2014-06-23
- Fixed a bug in the LAPIN implementation because of overflow and cleaned the code, and added some comments.
- v0.96k- 2014-06-22 (1 new algorithm)
- Added the LAPIN (aka LAPIN-SPAM) algorithm for sequential pattern mining. This is a first implementation in SPMF based on the LAPIN-LCI variation of LAPIN described in the technical report of LAPIN.
- Added the dECLAT and dCHARM algorithm for mining frequent itemsets. Those algorithms are respectively variations of the Eclat and Charm algorithms. The difference is that it uses the diffsets data structure rather than tidsets. We provide an implementation of dEclat using sets of integers to represent diffsets ("dEclat") and one version using bitsets ("dEclat_bitset"). For dCharm, only a version using bitsets is provided ("dCharm_bitset").
- v0.96h - 2014-06-15 (1 new algorithm)
- Added the DEFME algorithm for mining frequent generator itemsets using a depth-first search.
- v0.96g - 2014-06-14
- Fixed bugs in FEAT/ FSGP that occurred when multiple items per itemsets appeared in input sequences.
- v0.96f - 2014-06-11
- Optimized the code for association rule generation. Up to 10 times faster on some datasets.
- Improved the source code for closed association rule mining and merge some classes.
- Introduced a class ca.pfv.spmf.algorithms.ArraysAlgo to put all important algorithms on sorted list of integers that are shared by several algorithms (to remove some redundancy in the source code).
- v0.96e - 2014-06-10
- Optimization of the binary search in Apriori based algorithms (Apriori, AprioriClose, AprioriInverse...), as well as in FHM and HUI-Miner.
- Major optimizations of the Eclat and Charm algorithms. I have re-implemented most of the code.
- Converted the encoding of Java source code files from ISO-8859-1 to UTF-8 to remove warnings when compiling the code in Net Beans (Thanks to M. Witbrock for reporting this issue)
- Added a performance comparison with a closed source data mining library in the "performance" section of the website.
- three new algorithms:
- FEAT, FSGP and VGEN for mining frequent sequential generator patterns from a sequence database.
- fixed an array out of bound exception in the FPGrowth algorithm that occurred when all items are infrequent (thanks to Aman).
- v0.96c - 2014-04-30
- fixed a bug in association rule generation with CFPGrowth (AlgoCFPGrowth.java), thanks to Manperta Negara Situmorang.
- v0.96b - 2014-04-24
- Major optimization of all FP-Growth based algorithms (FPGrowth, FPGrowth_with_strings, CFPGrowth++), thanks to Dan Cappucio. The modification is to add mapItemLastNodes in the FPTree / MISTree classes (see the "performance" section of the website for an overview of the speed improvement).
- fixed a bug in the CMDeo algorithm that was causing an array out of bound exception
- v0.96 - 2014-04-06 (3 new algorithms)
- new algorithms:
- added the GoKrimp and SeqKrimp algorithms (by Thanh Lam Hoang et al) to discover compressing sequential patterns directly of by post-processing.
- added the FHM algorithm for mining high-utility itemsets
- new algorithms:
- v0.95d - 2014-03-10
- CFPGrowth has been renamed CFPGrowth++ since it includes the optimizations proposed in CFPGrowth++.
- fixed a bug in the VMSP algorithm (no result was shown)
- v0.95b - 2014-03-06
- fixed a bug in the TSP implementation
- fix some inconsistencies in the source code of some sequential pattern mining algorithms (thanks to C. Zhou)
- v0.95 - 2014-02-28 (major revision - 10
new algorithms)
- new algorithms for pattern mining:
- TKS for top-k sequential pattern mining
- TSP for top-k sequential pattern mining
- VMSP for maximal sequential pattern mining
- MaxSP for maximal sequential pattern mining
- ESTDEC for mining recent frequent itemsets from a stream (by Azadeh Soltani)
- MEIT (Memory Efficient Itemset-Tree), a data structure for targeted association rule mining
- CM-SPAM for sequential pattern mining
- CM-SPADE for sequential pattern mining
- CM-ClaSP for closed sequential pattern mining
- PASCAL for mining frequent itemsets and identifying generators
- added a few minor optimizations to Charm and Eclat
- added the possibility to generate association rules from the output of the CFPGrowth algorithm.
- refactoring of SPADE, Clasp, SPAM_AGP, GSP and PrefixSpan_AGP
- Updated the map of data mining algorithms.
- improved the documentation web page of the website to add the description of the file formats of each algorithm.
- fixed a bug in the ID3 algorithm implementation
- fixed a bug to use the hierarchical clustering algorithm in the GUI (thanks to A. Rai)
- new algorithms for pattern mining:
- v0.94d - 2014-01-25
- fixed a bug in the ARFF ResultConverter.java file.
- old jar file for this version
- old source code for this version
- old documentation for this version
- v0.94c - 2013-11-26
- fixed rounding inconsistencies among sequential pattern mining algorithms (thanks to A. Pramudita).
- v0.94b - 2013-10-07
- Optimized the BIDE+ algorithm.
- fixed a bug in the trimBeginingAndEnd method of PseudoSequenceBIDE.java for the BIDE+ algorithm.
- Cleaned the code of FPGrowth for the case of a tree with a single path (thanks to R. Loomba).
- v0.94 - 2013-08-12 (major revision - 6 new algorithms)
- Several new sequential pattern mining algorithms by
Antonio Gomariz Pe�alver:
- GSP,
- SPADE (regular and parallelized versions)
- ClaSP, a very efficient vertical algorithm for closed sequential pattern mining
- CloSpan,
- PrefixSpan and SPAM (alternative implementations)
- Closed sequential pattern mining by post-processing with PrefixSpan and SPAM.
- Also, new test files: contextCloSpan.txt, contextClaSP.txt and contextSPADE.txt
- Bug fixes
- fixed an important in the class AbstractOrderedItemset of SPMF 0.93, which have affected the result of several algorithms including the algorithm for mining MNR rules.(thanks to Faizal Feroz):
- fixed a bug in the class ItemsetTree (thanks to Faizal Feroz):
- fixed a bug of integer overflow for large datasets (e.g. accidents) that occurred in the hashcode function of Charm (class HashTable) and other algorithms using the same class (thanks to K. Srinvas Rao)
- fixed a bug in Charm (bug also introduced in 0.93 due to refactoring).
- fixed a bug in TNS/TopSeqRules (thanks to Peter Toth)
- Updated the map of data mining algorithms and documentation.
- fixed a bug in dataset generation that was introduced in version 0.93d.
- old documentation for this version.
- old source code for this version.
- old jar file for this version.
- added a new datasets page on the website.
- added support for the ARFF file format (a popular file format that represent a relational database table as a text file). The ARFF format can be used as input in the command line interface and graphical interface of SPMF by algorithms that take a transaction database as input (most itemset mining and association rule mining algorithms). This version support all features of ARFF except that (1) the character "=" is forbidden and (2) escape characters are not considered. Note that when the ARFF format is used, the performance will be less than if the native SPMF file format is used because a conversion has to be performed. However, this additional cost should be small. Note that SPMF also support a few other formats besides ARFF (see the last examples in the documentation on file conversion for more information). However, only the ARFF format is converted on-the-fly (other formats have to be converted manually before applying an algorithm). 36 datasets in the ARFF format can be found in the datasets page of this website.
- added a tool to convert the CSV format with positive integers to a transaction database in SPMF format.
- improved the documentation
- fixed a bug in the hierarchical clustering algorithm
- fixed a bug in the sequence database generator and transaction database generator.
- added the Hirate-Yamana algorithm to the GUI interface and command line interface
- Several new sequential pattern mining algorithms by
Antonio Gomariz Pe�alver:
- v 0.93 - 2013-05-09 (major
revision - 7 new algorithms)
- Several packages and files have been renamed for a better organization of the source code.
- Merged some files that were duplicated in various packages for less redundancy.
- Optimized several Apriori-based algorithms such as AprioriRare and AprioriInverse.
- Some algorithms have been optimized to use better data structures such as using arrays instead of list of integers.
- Added 7 algorithms to the GUI: Apriori_TIDClose, AprioriTID, Apriori - Association rules, Sporadic association rules, Indirect association rules, IGB, MNR.
- Fixed some small bugs in the source code.
- Tried to standardize as much as possible the output files written by the algorithms so that algorithms performing the same task will output the same file format.
- The CHARM-MFI algorithms was not generating the correct result. I have found that the problem is the algorithm itself, which is incorrect as it is described in Szathmary (2006) for some special cases. I have adapted the algorithm so that it generates the correct result.
- I have removed four less popular algorithms that were not well-documented and not offered in the release version of SPMF: the algorithm for mining pseudo-closed itemsets, the Guigues-Duquenne basis, proper basis and the structural basis of association rules. If you want these algorithms, you can download version 0.92 of SPMF to get them.
- Added the maximum pattern length constraint to PrefixSpan and SPAM algorithms.
- v 092c - 2013-04-08
- fixed a bug that occurred when prefixspan_with_strings was called from the user interface or command line.
- old documentation for this version.
- old developer's guide for this version.
- old source code for this version.
- old jar file for this version.
- v 092b - 2013-03-14
- fixed a bug in the calculation of the lift measure for association rules.
- v 092 - 2013-03-05 (1 new algorithm)
- added an implementation of HUI-Miner, one of the best algorithms for high utility itemset mining.
- v 091 - 2012-12-29
- added an implementation of Apriori that uses a hash-tree to store candidates to calculate the support and generate candidates more efficiently (it is named "Apriori_with_hash_tree" or "AprioriHT"). It can be up to twice faster than the previous version (a performance comparison).
- added a version of FPGrowth that accepts strings instead of integers as input (FPGrowth_itemsets_with_strings)
- v 090 - 2012-12-25:
- added a tool to generate transaction databases.
- added a tool to generate sequence databases.
- added a tool to convert sequence databases to the SPMF format.
- added a command line interface to run algorithms from the command
line.
- added an implementation of TNR for top-k non-redundant association rule mining.
- added an implementation of TNS for top-k non-redundant sequential rule mining.
- clean the source code a little bit.
- fixed some small bugs in the Indirect, FHSAR and ZART algorithms.
- added an implementation of CFPGROWTH for mining itemsets with multiple support thresholds (implemented by Azadeh Soltani).
- v 0.88 - 2012-08-22:
- added an implementation of MSAPRIORI for mining itemsets with multiple support thresholds (implemented by Azadeh Soltani).
- fixed a small bug in the red-black tree implementation used by TOPKRULES and TOPSEQRULES
- fixed a small bug in Cluster.java (thanks to F. Jafari)
- fixed a small bug in TRULEGROWTH.
- added implementations of TRULEGROWTH and BIDE+ that accepts strings instead of integers as input.
- v 0.87 - 2012-07-28:
- improved the user interface so that (1) example parameter values are shown for each parameter and (2) that percentage values can be entered either in decimal format (e.g. 0.5) or as a percentage (e.g. 50%).
- fixed a bug in the hierarchical clustering algorithm in the GUI version of SPMF
- v 0.86 - 2012-07-26:
- modified the user interface so that algorithms are presented by their category in the combo box such as "sequential pattern mining", "sequential rule mining", "itemset mining", "clustering", etc.
- optimized the basic Apriori implementation with binary search for checking subsets of candidates, arrays of integers instead of lists, and more.
- v 0.85 - 2012-07-17:
- added several algorithms to the GUI version of SPMF: K-MEANS, TWO-PHASE, VME, ZART, RELIM, RULEGEN, SEQ-DIM, etc.
- improved the version of K-Means and the hierarchical clustering algorithm so that it can work with vectors and cleaned the code..
- added some small optimizations to the RELIM and ZART implementations,
- cleaned the implementation of the algorithm for mining pseudo-closed itemsets,
- cleaned the code of algorithms for mining multi-dimensional sequential patterns and modified them so that they save the results to a file.
- cleaned the source code of Apriori-based algorithms.
- v 0.84 - 2012-07-15: added a few algorithms for building, updating and querying an Itemset-Tree. An itemset tree is a special structure representing a database that allows efficiently generating targeted association rules, frequent itemsets and to get the support of any itemset. This structure can be updated incrementally (only available in the source code version of SPMF).
- v. 0.83 - 2012-07-04: added the possibility of mining association rule with the lift measure and the minlift threshold.
- v. 0.82 - 2012-06-30: fixed a bug in the SPAM implementation that occurred when minsup =0 (thanks to D. Bhatt).
- v. 0.81 - 2012-04-13: improved the SPAM implementation. The number of bits by sequence is now variable. The algorithm is therefore more memory efficient and can run on larger datasets with longer sequences.
- v. 0.80 - 2012-04-08: improved the user interface (thanks to Hanane Amirat), changed the license of the software to GPL v3, fixed a minor bug in the TRuleGrowth algorithm, cleaned the source code of several algorithms by removing some unused methods.
- v. 0.79 - 2012-03-17: added five Apriori-based algorithms to the GUI version (Apriori, AprioriClose, AprioriRare, AprioriInverse, UApriori) and made some minor improvements.
- v. 0.78 - 2012-03-05:
- Added the TRULEGROWTH for mining sequential rules with the window size constraint.
- Added the TOPKRULES algorithm for mining the top-k association rules in a transaction database.
- Added the TOPSEQRULES algorithm for mining the top-k sequential rules in a sequence database.
- Added an implementation of FPGROWTH that saves the result to a file instead of keeping the result into memory.
- Cleaned the implementation of PREFIXSPAN. I removed some unused variables in the pseudo-sequence implementation (thanks to shouwangji@___ for reporting this),
- Added an implementation of the KD-TREE data structure,
- Added a simple graphical user interface (ca.pfv.spmf.gui.MainWindow) that allows to run 17 main algorithms (other algorithms will be added to the user interface later).
- v.0.77 - 2011-10-28: Added an implementation of FHSAR for association rule hiding.
- v.0.76 - 2011-10-22: Added faster and more memory efficient implementations of AprioriTID, ECLAT and CHARM that use bit vectors for representing tids sets.
- v.0.75 - 2011-10-18: Added an implementation of INDIRECT for mining "indirect association rules".
- v.0.74 - 2011-08-11: Added an implementation of SPAM for sequential pattern mining
- v.0.73 - 2011-09: cleaned the implementation of PREFIXSPAN and BIDE+ and made some optimizations, added an implementation of RULEGEN for generating sequential rules from sequential patterns.
- v.0.72 - 2011-07: Added implementations of RULEGROWTH for mining sequential rules,ID3 for creating decision trees, VME for mining erasable itemsets. Also, I cleaned a little bit the implementations of K-Means, the hierarchical clustering algorithm, AprioriTID and Apriori_TIDClose, CMRules and CMDeo.
- v.0.71 - 2011-02-01: fixed a bug in the CMRULES and CMDEO algorithms.
- v 0.70 - 2011-01-06: added an implementation of the H-MINE algorithm for mining frequent itemsets.
- v 0.69- 2010-11-27: added two implementations of the DCI_CLOSED algorithm for mining frequent closed itemsets (one straigthforward implementation and one with optimizations).
- v 0.68 - 2010-11-09: improved the performance of all Apriori-based algorithms. Also, I have added implementations of four algorithms:
- the TWO-PHASE algorithm for mining high-utility itemsets, Apriori_TIDClose for frequent closed itemset mining, and CMRULES and CMDEO algorithms for mining sequential rules.
- v 0.67 - 2010-10-07: added an implementation of U-Apriori for mining frequent itemsets from uncertain data, fixed a bug in the CHARM and ECLAT algorithms
- v 0.66 - 2010-08-25: added an implementation of AprioriTID and some code for generating association rules by using FP-GROWTH.
- v 0.65 - 2010-08-14: fixed a bug in the BIDE+ algorithm (thanks to Brock for reporting it)
- v 0.64 - 2010-07-19: minor changes (add comments, fixed minor bugs, etc.)
- v 0.63 - 2010-04: minor changes (add comments, fixed minor bugs, etc.)
- v.062 - 2010-04-11: fixed a bug in the triangular matrix used by the CHARM and ECLAT algorithms.
- v.061 - 2010-03-20: implementation of FP-GROWTH, fixed a bug in BIDE+ (thanks to G. Bruno for reporting it) and fixed a bug in RELIM
- v.060 - 2010-03-15: fixed a bug in CHARM/ECLAT occurring if items are missing in the input file (thanks to A. Pardeshi for reporting it)
- v.059 - 2010-02-05: fixed a bug in the BIDE+ implementation (thanks to G. Bruno for reporting it)
- v.0.58 - 2009-12-15: implementations of the CHARM, CHARM-MFI and ECLAT algorithms
- v.0.57 - 2009-11: implementation of the BIDE+ algorithm
- v.0.56 : 2009-10-09: implementations of the RELIM and PREFIXSPAN algorithms
- v.0.55 : 2009-08-01: cleaned the code and fixed some bugs
- ...
- v.050 - 2009-05-31 implementation of APRIORI-RARE and the APRIORI algorithm for mining association rules
- v.049 - 2008-12-07: initial release.
{kind=link}
{kind=link}
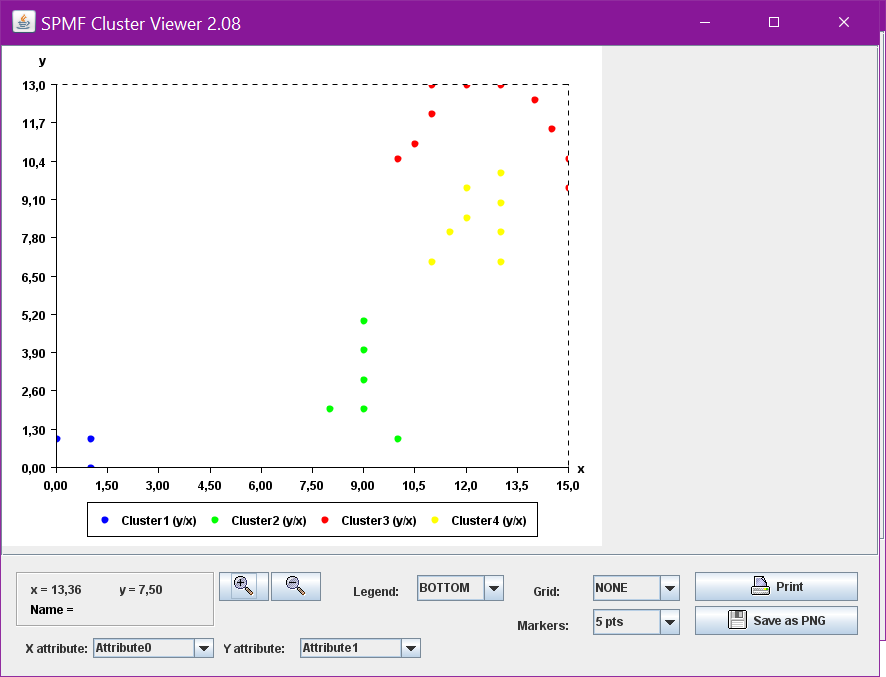{kind=link}
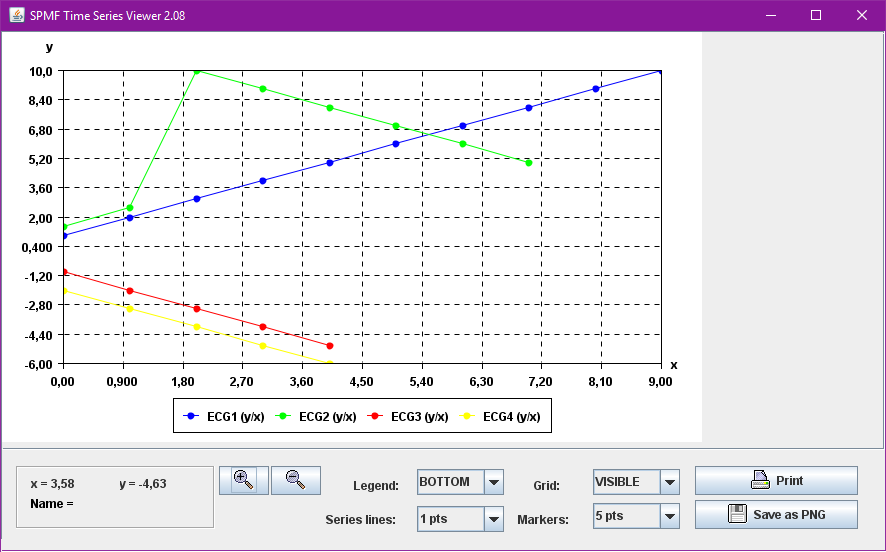{kind=link}
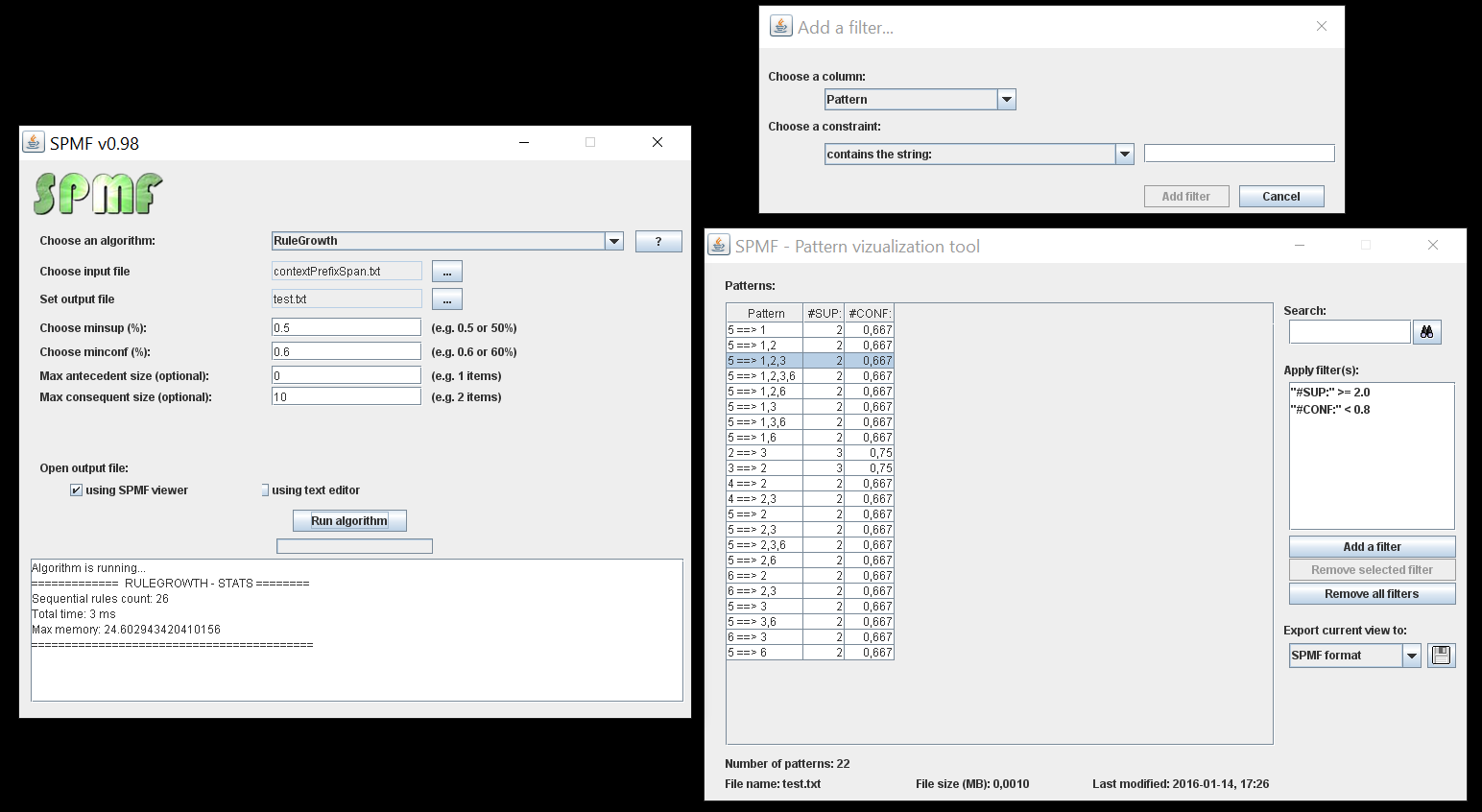{kind=link}
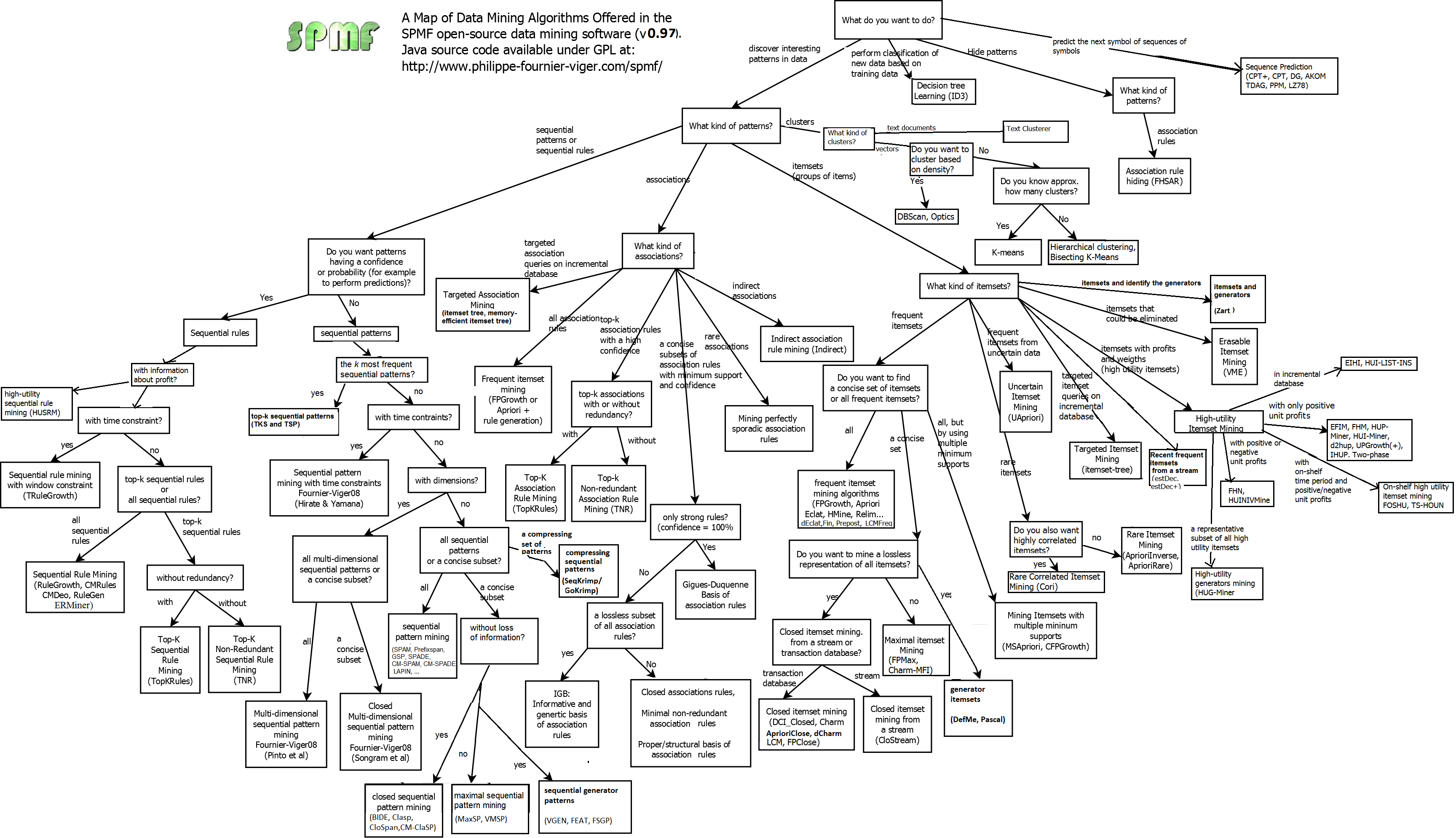{kind=link}
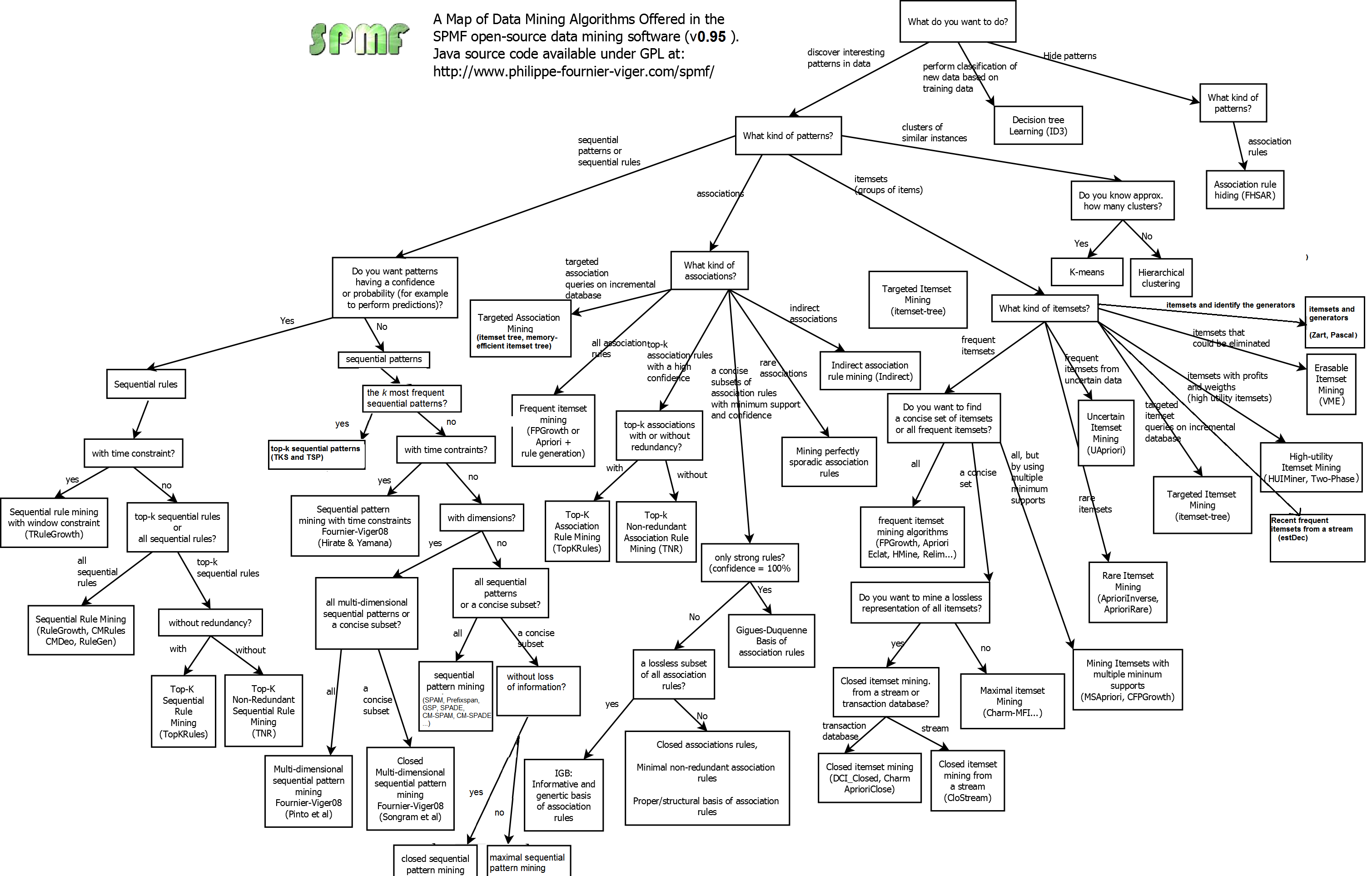{kind=link}
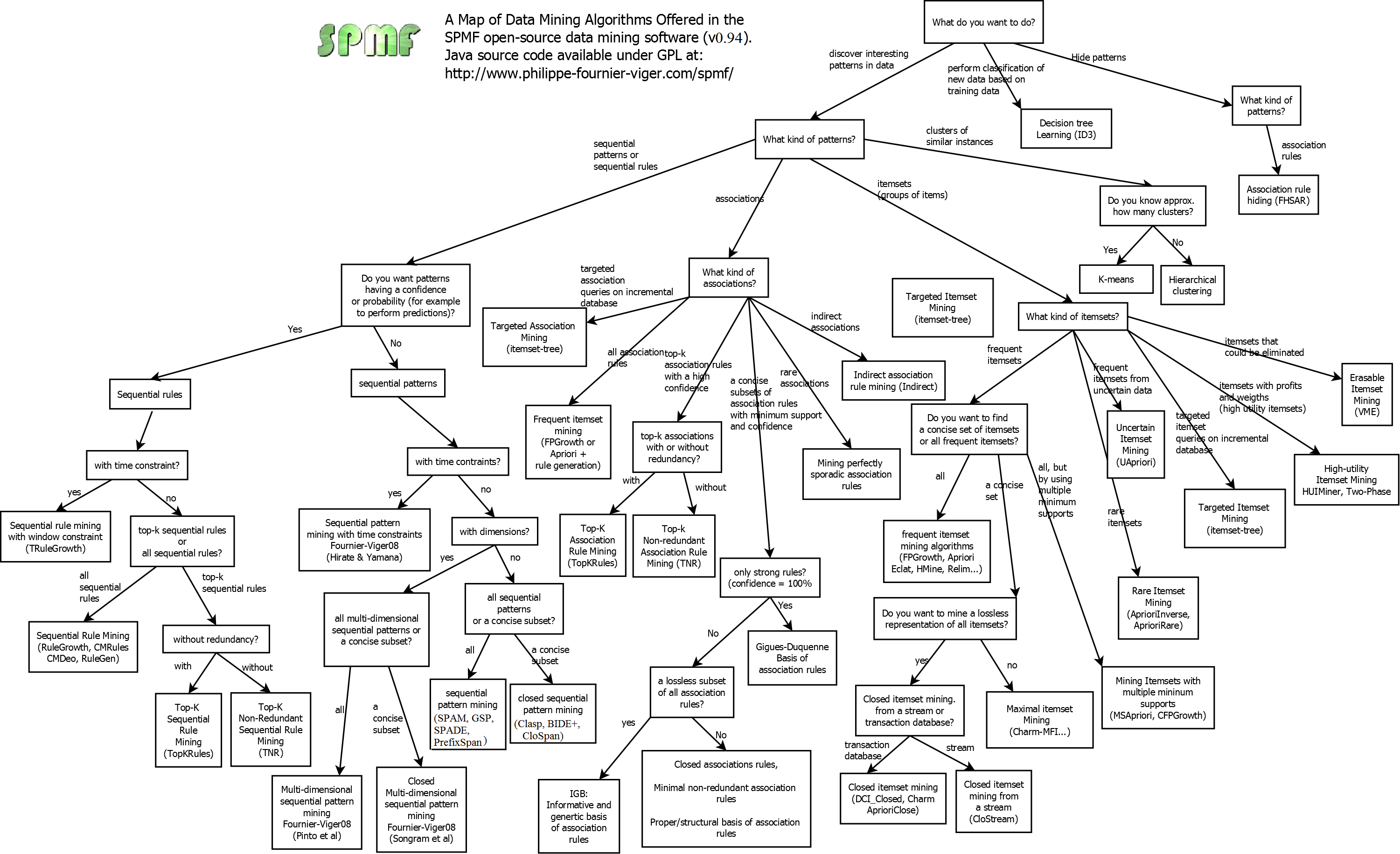{kind=link}