Algorithms
SPMF offers implementations of the following data mining algorithms.
Sequential Pattern Mining
These algorithms discover sequential patterns in a set of sequences. For a good overview of sequential pattern mining algorithms, please read this survey paper.
- algorithms for mining sequential patterns
(subsequences that appear in many sequences) of a sequence database
- the CM-SPADE algorithm (Fournier-Viger et al., 2014, 📊 slides)
- the CM-SPAM algorithm (Fournier-Viger et al., 2014, 📊 slides)
- the FAST algorithm (Salvemini et al., 2011)
- the GSP algorithm (Srikant et al., 1996)
- the LAPIN (aka LAPIN-SPAM) algorithm (Yang et al., 2005)
- the PrefixSpan algorithm (Pei et al., 2004, 📊 slides ▶ video)
- the SPADE algorithm (Zaki et al., 2001)
- the SPAM algorithm (Ayres et al., 2002)
- algorithms for mining closed sequential patterns in a sequence database
- the ClaSP algorithm (Gomariz et al., 2013)
- the CM-ClaSP algorithm (Fournier-Viger et al., 2014, 📊 slides)
- the CloFAST algorithm (Fumarola et al., 2016)
- the CloSpan algorithm (Yan et al., 2003)
- the BIDE+ algorithm (Wang et al., 2007)
- algorithms for mining maximal sequential patterns in a sequence database
- the VMSP algorithm (Fournier-Viger et al., 2014, 📊 slides)
- the MaxSP algorithm (Fournier-Viger et al., 2013, 📊 slides)
- algorithms for mining the top-k sequential patterns in a sequence database
- the TKS algorithm (Fournier-Viger et al., 2013, 📊 slides)
- the TSP algorithm (Tzvetkoz et al., 2003)
- the Skopus algorithm – top-k sequential patterns using leverage and significance (Petijean et al., 2016)
- algorithms for mining sequential generator patterns in a sequence database
- the VGEN algorithm (Fournier-Viger et al., 2014)
- the FEAT algorithm (Gao et al., 2008)
- the FSGP algorithm (Yi et al., 2011)
- algorithms for mining nonoverlapping sequential patterns
in one or many sequences of symbols/characters (can count multiple occurrences per sequence)
- the NOSEP algorithm (Wu et al., 2018) new
- algorithms for mining compressing sequential patterns
- the GoKrimp and SeqKrimp algorithms (Lam et al., 2012; Lam et al., 2014)
- the HMG-GA and HMG-SA algorithms – compressing patterns in genome sequences (Nawaz et al., 2025) new
- algorithm for identifying the top-k quantile based cohesive sequential patterns
in a single sequence or in multiple sequences
- the QCSP algorithm (Feremans et al., 2019)
- algorithms for mining multidimensional sequential patterns
in a multidimensional sequence database
- the SeqDIM algorithm – frequent multidimensional sequential patterns (Pinto et al., 2001)
- the Songram et al. algorithm – frequent closed multidimensional sequential patterns (Songram et al., 2006)
- the Fournier-Viger et al. algorithm – a sequential pattern mining algorithm combining
features from well-known algorithms with original extensions
(Fournier-Viger et al., 2008):
- mining sequences with minimum support by database-projection (based on PrefixSpan, Pei et al., 2004)
- mining sequences with min/max time interval and sequence time length (based on Hirate-Yamana, 2006)
- mining closed sequences (based on BIDE+, Wang et al., 2007)
- mining multi-dimensional sequences (based on Pinto et al., 2001)
- mining closed multi-dimensional sequences (based on Songram et al., 2006 and Pasquier et al., 1999)
- mining sequences with integer-valued items and automatic clustering of values (Fournier-Viger et al., 2008)
- algorithm for mining high-utility sequential patterns in a sequence database
- the USPAN algorithm (Yin et al., 2012)
- algorithm for mining cost-efficient sequential patterns
(a.k.a. low-cost high utility sequential patterns)
- the CorCEPB algorithm – binary utility with cost values (Fournier-Viger et al., 2020, 📊 slides ▶ video) new
- the CEPB algorithm – binary utility with cost values (positive utility only) (Fournier-Viger et al., 2020, 📊 slides ▶ video) new
- the CEPN algorithm – numeric utility with cost values (Fournier-Viger et al., 2020, 📊 slides ▶ video) new
- algorithm for mining high-utility probability sequential patterns
in a sequence database
- the PHUSPM algorithm (Zhang et al., 2018)
- the UHUSPM algorithm (Zhang et al., 2018)
- algorithm for progressive sequential pattern mining
with convergence guarantees
- the ProSecCo algorithm (Servan-Schreiber et al., 2018)
- algorithms for mining sequential patterns with flexible constraints
in a time-extended sequence database (e.g. MOOC data)
- the SPM-FC-L algorithm (Song et al., 2022) new
- the SPM-FC-P algorithm (Song et al., 2022) new
- the Occur algorithm – finds all occurrences of sequential patterns in sequences by post-processing
- algorithms for mining patterns in sequences of events described by time intervals
(Time Interval Related Pattern — TIRP — mining)
- the FastTIRP algorithm (Fournier-Viger et al., 2022) new
- the VertTIRP algorithm (Mordvanyuk et al., 2021) new
Sequential Rule Mining
These algorithms discover sequential rules in a set of sequences.
- algorithms for mining sequential rules in a sequence database
- the ERMiner algorithm (Fournier-Viger et al., 2014)
- the RuleGrowth algorithm (Fournier-Viger et al., 2011, Fournier-Viger et al., 2015, 📊 slides ▶ video)
- the CMRules algorithm (Fournier-Viger et al., 2010, 📊 slides ▶ video)
- the CMDeo algorithm (Fournier-Viger et al., 2010)
- the RuleGen algorithm (Zaki et al., 2001)
- algorithms for mining sequential rules in a sequence database
with the window size constraint
- the TRuleGrowth algorithm (Fournier-Viger, 2012, Fournier-Viger et al., 2015)
- algorithms for mining top-k sequential rules in a sequence database
- the TopSeqRules algorithm (Fournier-Viger et al., 2011, 📊 slides)
- the TopSeqClassRules algorithm – top-k class sequential rules (variation of Fournier-Viger et al., 2011)
- the TNS algorithm – top-k non-redundant sequential rules (Fournier-Viger, 2013)
- algorithm for mining high-utility sequential rules in a sequence database
- the HUSRM algorithm (Zida et al., 2015)
Sequence Prediction
These algorithms predict the next symbol of a sequence based on a set of training sequences.
- the Compact Prediction Tree+ (CPT+) algorithm (Gueniche et al., 2015, 📊 slides ▶ video)
- the Compact Prediction Tree (CPT) algorithm (Gueniche et al., 2013, ▶ video)
- the First-order Markov Chains (PPM – order 1) (Clearly et al., 1984)
- the Dependency Graph (DG) (Padmanabhan, 1996)
- the All-k-Order Markov Chains (AKOM) (Pitkow, 1999)
- the TDAG (Laird & Saul, 1994)
- the LZ78 (Ziv, 1978)
Itemset Mining
These algorithms discover interesting itemsets (sets of values) in a transaction database. For a good overview, please read this survey paper.
- algorithms for discovering frequent itemsets in a transaction database
- the Apriori algorithm (Agrawal & Srikant, 1994, ▶ video) new
- the AprioriTID algorithm (Agrawal & Srikant, 1994)
- the FP-Growth algorithm (Han et al., 2004)
- the Eclat algorithm (Zaki, 2000, ▶ video)
- the dEclat algorithm (Zaki and Gouda, 2001, 2003)
- the Relim algorithm (Borgelt, 2005)
- the H-Mine algorithm (Pei et al., 2007)
- the LCMFreq algorithm (Uno et al., 2004)
- the PrePost algorithm (Deng et al., 2012)
- the PrePost+ algorithm (Deng & Lv, 2015)
- the FIN algorithm (Deng et al., 2014)
- the DFIN algorithm (Deng et al., 2016)
- the NegFIN algorithm (Aryabarzan et al., 2018)
- the DIC algorithm (Brin et al., 1997) new
- the TM algorithm (Song et al., 2006) new
- the SAM algorithm (Borgelt et al., 2009) new
- the LinearTable algorithm (Lu et al., 2023) new
- algorithms for discovering frequent closed itemsets in a transaction database
- the FPClose algorithm (Grahne and Zhu, 2005)
- the Charm algorithm (Zaki and Hsiao, 2002)
- the dCharm algorithm (Zaki and Gouda, 2001)
- the DCI_Closed algorithm (Lucchese et al., 2004)
- the LCM algorithm (Uno et al., 2004)
- the AprioriClose (aka Close) algorithm (Pasquier et al., 1999)
- the AprioriTID Close algorithm (Pasquier et al., 1999, Agrawal & Srikant, 1994)
- the NAFCP algorithm (Le et al., 2015)
- the NEclatClosed algorithm (Aryabarzan et al., 2021)
- the CARPENTER algorithm (Pan et al., 2003) new
- the DBVMiner algorithm (Vo et al., 2012) new
- the NEWCHARM algorithm (Ye et al., 2015) new
- algorithms for recovering all frequent itemsets from frequent closed itemsets
- the LevelWise algorithm (Pasquier et al., 1999)
- the DFI-Growth algorithm (Huang et al., 2019)
- the DFI-List algorithm (Wu et al., 2020)
- algorithms for discovering frequent maximal itemsets in a transaction database
- the FPMax algorithm (Grahne and Zhu, 2003)
- the Charm-MFI algorithm (Szathmary et al., 2006)
- the CARPENTER-MAX algorithm (Pan et al., 2003) new
- the GENMAX algorithm (Gouda et al., 2005) new
- algorithms for mining frequent itemsets with multiple minimum supports
- the MSApriori algorithm (Liu et al., 1999)
- the CFPGrowth++ algorithm (Uday & Reddy, 2011, Hu & Chen, 2006)
- algorithms for mining generator itemsets in a transaction database
- the DefMe algorithm (Soulet & Rioult, 2014)
- the Talky-G and Talky-G-Diffset algorithms (Szathmary et al., 2009) new
- the Pascal algorithm (Bastide et al., 2002)
- the Zart algorithm (Szathmary et al., 2007)
- algorithms for mining rare itemsets and/or correlated itemsets
in a transaction database
- the AprioriInverse algorithm – perfectly rare itemsets (Koh & Roundtree, 2005, ▶ video) and AprioriTIDInverse (vertical structure variant)
- the AprioriRare algorithm – minimal rare itemsets and frequent itemsets (Szathmary et al., 2007, ▶ video) and AprioriTIDRare (vertical structure variant)
- the CORI algorithm – minimal rare correlated itemsets using support and bond measures (Bouasker et al., 2015, ▶ video)
- the RP-Growth algorithm (Tsang et al., 2011) new
- algorithms for performing targeted and dynamic queries about
association rules and frequent itemsets
- the Itemset-Tree – incrementally updatable data structure with query algorithms (Kubat et al., 2003)
- the Memory-Efficient Itemset-Tree (Fournier-Viger, 2013, 📊 slides)
- algorithms to discover frequent itemsets in a stream
- the estDec algorithm – recent frequent itemsets (Chang & Lee, 2003)
- the estDec+ algorithm – recent frequent itemsets (Shin et al., 2014)
- the CloStream algorithm – frequent closed itemsets (Yen et al., 2009)
- the U-Apriori algorithm – frequent itemsets in uncertain data (Chui et al., 2007)
- the VME algorithm – erasable itemsets (Deng & Xu, 2010)
- algorithms to discover fuzzy frequent itemsets in a quantitative transaction database
- the FFI-Miner algorithm (Lin et al., 2015)
- the MFFI-Miner algorithm (Lin et al., 2016)
- the OPUS-Miner algorithm – self-sufficient itemsets (Webb et al., 2014)
- algorithms to discover compressing itemsets based on the MDL principle
- the KRIMP algorithm (Vreeken et al., 2011) new
- the SLIM algorithm (Smets et al., 2012) new
- the GRIMP algorithm (Nawaz et al., 2025) new
- the HMP-SA algorithm (Chen et al., 2026) new
- the HMP-HC algorithm (Chen et al., 2026) new
- algorithms to discover the top-k most frequent itemsets
- the Apriori(top-k) algorithm (modified Apriori) new
- the FPGrowth(top-k) algorithm (modified FP-Growth) new
Episode Mining
These algorithms discover patterns (episodes) in a single sequence of events. For a good overview, please read this survey paper.
- algorithms for mining frequent episodes
- the EMMA algorithm – frequent episodes based on head frequency (Kuo-Yu et al., 2008)
- the AFEM algorithm – frequent episodes based on head frequency (Fournier-Viger et al., 2022) new
- the MINEPI+ algorithm – frequent episodes based on head frequency (Kuo-Yu et al., 2008)
- the MINEPI algorithm – frequent episodes, minimal occurrences, no simultaneous events (Mannila & Toivonen, 1997)
- the TKE algorithm – top-k most frequent episodes (Fournier-Viger et al., 2020)
- the MaxFEM algorithm – maximal frequent episodes (Fournier-Viger et al., 2022) new
- the EMDO algorithm – frequent parallel episodes based on distinct occurrences (Ouarem et al., 2024) new
- algorithms for mining episode rules
- the POERM algorithm – partially-ordered episode rules, non-overlapping support (Fournier-Viger et al., 2021, ▶ video 📊 slides) new
- the POERM-ALL algorithm – all partially-ordered episode rules (Fournier-Viger et al., 2021, ▶ video 📊 slides) new
- the POERMH algorithm – partially-ordered episode rules, head support (Fournier-Viger et al., 2021, ▶ video 📊 slides) new
- the NONEPI algorithm – episode rules using non-overlapping frequency (Ouarem et al., 2021)
- the EMDO-Rules and EMDOP-Rules algorithms – episode rules from parallel episodes (Ouarem et al., 2024) new
- algorithms to generate episode rules (Mannila & Toivonen, 1997) using output of TKE, AFEM, EMMA or MINEPI+ new
- algorithms for mining high-utility episodes in a sequence of complex events
with utility information
- the HUE-SPAN algorithm (Fournier-Viger et al., 2019, 📊 slides) new
- the US-SPAN algorithm (Wu et al., 2013)
- the TUP algorithm – top-k high-utility episodes (Rathore et al., 2016)
- algorithms for mining nonoverlapping sequential patterns
in one or many sequences of symbols
- the NOSEP algorithm (Wu et al., 2018) new
- algorithms for mining frequent sequential patterns with periodic wildcard gaps
in a sequence of characters
- the MAPD algorithm (Wu, Y. et al., 2014)
- algorithms for mining self-adaptive one-off weak-gap strong sequential patterns
in a sequence of characters
- the OWSP-Miner algorithm (Wu, Y. et al., 2022) new
Periodic Pattern Mining
These algorithms discover patterns that periodically appear in a sequence of records (e.g. transactions).
- algorithms for finding frequent periodic patterns in a single sequence of events
- the PFPM algorithm (Fournier-Viger et al., 2016, 📊 slides ▶ video)
- algorithms for mining stable periodic itemsets
in a sequence of events with or without timestamps
- the SPP-Growth algorithm (Fournier-Viger et al., 2019, 📊 slides ▶ video)
- the TSPIN algorithm – top-k stable periodic frequent itemsets (Fournier-Viger et al., 2021) new
- algorithms for mining locally periodic patterns
in a transaction database with or without timestamps
- the LPP-Growth algorithm (Fournier-Viger, 2020, 📊 slides) new
- the LPPM_breadth algorithm (Fournier-Viger, 2020, 📊 slides) new
- the LPPM_depth algorithm (Fournier-Viger, 2020, 📊 slides) new
- algorithms for discovering periodic patterns that are significant or non-redundant
- the NPFPM algorithm – non-redundant periodic frequent itemsets (Afriyie et al., 2020, 2021) new
- the PPFP algorithm – productive periodic frequent itemsets (Nofong, 2016) new
- the SRPFPM algorithm – self-reliant periodic frequent patterns (Nofong et al., 2021) new
- algorithms for mining periodic high-utility itemsets
in a sequence of transactions with utility information
- the PHM algorithm (Fournier-Viger et al., 2016, 📊 slides ▶ video)
- the PHMN algorithm (2023) – periodic high-utility itemsets with positive or negative utility new
- the PHMN+ algorithm (2023) – periodic high-utility itemsets with positive or negative utility new
- the PHM_irregular algorithm – irregular (non-periodic) high-utility itemsets (variation of PHM)
- algorithms for finding periodic patterns in multiple sequences of events
- the MPFPS_BFS algorithm (Fournier-Viger et al., 2019, 📊 slides)
- the MPFPS_DFS algorithm (Fournier-Viger et al., 2019, 📊 slides)
- algorithms for mining rare correlated periodic patterns common to multiple sequences
- the MRCPPS algorithm (Fournier-Viger et al., 2020) new
Graph Pattern Mining new
These algorithms discover patterns in graphs.
- algorithms for mining frequent subgraphs
- the TKG algorithm – top-k frequent subgraphs (Fournier-Viger, 2019, 📊 slides)
- the gSpan algorithm – all frequent subgraphs (Yan et al., 2002)
- the cgSpan algorithm – frequent closed subgraphs (graph database or single graph; traditional or MNI support) (Shaul et al., 2021) new
- algorithms for mining patterns in a dynamic attributed graph
- the TSeqMiner algorithm (Fournier-Viger et al., 2019)
- the AER-Miner algorithm (Fournier-Viger et al., 2020, 📊 slides)
High-Utility Pattern Mining
These algorithms discover patterns having a high utility (importance) in different kinds of data. For a good overview, read the survey paper or the high utility-pattern mining book.
- algorithms for mining high-utility itemsets
in a transaction database having profit information
- the EFIM algorithm (Zida et al., 2016, 📊 slides)
- the FHM algorithm (Fournier-Viger et al., 2014, 📊 slides ▶ video)
- the HUI-Miner algorithm (Liu & Qu, 2012, ▶ video)
- the HUP-Miner algorithm (Krishnamoorthy, 2014)
- the mHUIMiner algorithm (Peng et al., 2017)
- the UFH algorithm (Dawar et al., 2017)
- the HMiner algorithm (Krishnamoorthy, 2017)
- the ULB-Miner algorithm (Duong et al., 2018) new
- the IHUP algorithm (Ahmed et al., 2009)
- the Two-Phase algorithm (Liu et al., 2005)
- the UP-Growth algorithm (Tseng et al., 2011)
- the UP-Growth+ algorithm (Tseng et al., 2013)
- the UP-Hist algorithm (Dawar et al., 2015)
- the d2HUP algorithm (Liu et al., 2012)
- the FHIM algorithm (Sahoo et al., 2015)
- the PUCPMiner algorithm (Patel et al., 2022) new
- the RMiner algorithm (Sra et al., 2023) new
- algorithm for efficiently mining high-utility itemsets with length constraints
- the FHM+ algorithm (Fournier-Viger et al., 2016, 📊 slides)
- algorithm for mining correlated high-utility itemsets
- the FCHM_bond algorithm – bond measure (Fournier-Viger et al., 2016, 📊 slides ▶ video)
- the FCHM_allconfidence algorithm – all-confidence measure (Fournier-Viger et al., 2016, 📊 slides)
- the ECHUM algorithm (Ramesh et al., 2022) - obtained from Github aman955 under the GPL license
- algorithm for mining high-utility itemsets with negative unit profit values
- the FHN algorithm (Fournier-Viger et al., 2014, 📊 slides)
- the HUINIV-Mine algorithm (Chu et al., 2009)
- algorithms for mining multi-level or cross-level high-utility itemsets
with a taxonomy
- the CLH-Miner (Fournier-Viger et al., 2020, 📊 slides)
- the FEACP (Tung et al., 2022) new
- the MLHUI-Miner (Cagliero et al., 2017)
- algorithm for mining low-cost high-utility itemsets
- the LCIM algorithm (Fournier-Viger et al., 2022) new
- algorithm for mining frequent high-utility itemsets
- the FHMFreq algorithm (variation of FHM, Fournier-Viger et al., 2014)
- algorithm for mining on-shelf high-utility itemsets
(items with time periods)
- the FOSHU algorithm (Fournier-Viger et al., 2015, 📊 slides)
- the TS-HOUN algorithm (Lan et al., 2014)
- algorithm for incremental high-utility itemset mining
- the EIHI algorithm (Fournier-Viger et al., 2015, 📊 slides)
- the HUI-LIST-INS algorithm (Lin et al., 2014)
- algorithm for incremental closed high-utility itemset mining
- the IncCHUI algorithm (Dam et al., 2018) - obtained from Github under the GPL license
- algorithm for mining concise representations of high-utility itemsets
- the HUG-Miner – high-utility generators (Fournier-Viger et al., 2014, 📊 slides)
- the GHUI-Miner – generators of high-utility itemsets (Fournier-Viger et al., 2014, 📊 slides)
- the MinFHM – minimal high-utility itemsets (Fournier-Viger et al., 2016, 📊 slides ▶ video)
- the EFIM-Closed – closed high-utility itemsets (Fournier-Viger et al., 2016, 📊 slides)
- the CHUI-Miner – closed high-utility itemsets (Wu et al., 2015)
- the CLS-Miner – closed high-utility itemsets (Dam et al., 2019) new
- the HMiner_Closed – closed high-utility itemsets (Nguyen et al., 2019) new
- the CHUD – closed high-utility itemsets (Tseng et al., 2015)
- the CHUI-Miner(Max) – maximal high-utility itemsets (Wu et al., 2019) new
- the HUCI_Miner – closed high-utility itemsets and generators (Sahoo et al., 2015) new
- algorithm for mining the skyline high-utility itemsets
- the SkyMine algorithm (Goyal et al., 2015)
- the SFUI_UF algorithm – skyline frequent high-utility itemsets (Song et al., 2021) new
- the SFU_CE algorithm – skyline frequent high-utility itemsets (Song et al., 2021, 📊 slides) new
- the SFUPMinerUemax algorithm (Lin et al., 2016)
- the EMSFUI_D algorithm (Liu et al., 2022) new
- the EMSFUI_B algorithm (Liu et al., 2022) new
- algorithm for mining the top-k high-utility itemsets
- the TKU algorithm (Tseng et al., 2015) - obtained from the UP-Miner under the GPL license
- the TKO-Basic algorithm (Tseng et al., 2015)
- the THUI algorithm (Krishnamoorthy, 2019) new
- algorithms for mining the top-k high-utility itemsets from a data stream
- the FHMDS and FHMDS-Naive algorithms (Dawar et al., 2017)
- algorithm for mining quantitative high-utility itemsets
- the FHUQI-Miner algorithm (Nouioua et al., 2021, 📊 slides) new
- the VHUQI algorithm (Wu et al., 2014)
- the TKQ algorithm – top-k patterns (Nouioua et al., 2021, 📊 slides ▶ video) new
- the CHUQI-Miner – correlated quantitative high-utility itemsets (Nouioua et al., 2021, 📊 slides ▶ video) new
- algorithm for mining high-utility sequential rules in a sequence database
- the HUSRM algorithm (Zida et al., 2015)
- algorithm for mining high-utility sequential patterns in a sequence database
- the USPAN algorithm (Yin et al., 2012)
- algorithm for mining cost-efficient sequential patterns
(low-cost high-utility)
- the CorCEPB algorithm - mine patterns in sequences with binary utility information and cost values (Fournier-Viger et al., 2020, 📊 slides ▶ video) new
- the CEPB algorithm - mine patterns in sequences with binary utility information and cost values - consider only sequence with positive utility (Fournier-Viger et al., 2020, 📊 slides) new
- the CEPN algorithm - mine patterns in sequences with numeric utility information and cost values (Fournier-Viger et al., 2020, 📊 slides ▶ video) new
- algorithm for mining high-utility probability sequential patterns
- the PHUSPM algorithm (Zhang et al., 2018)
- the UHUSPM algorithm (Zhang et al., 2018)
- algorithm for heuristically mining the top-k high-utility itemsets
- the TKU-CE algorithm (Song et al., 2021) new
- the TKU-CE+ algorithm (Song et al., 2021) new
- algorithm for mining high-utility itemsets using evolutionary algorithms,
swarm intelligence or other meta-heuristics
- the HUIM-AF algorithm (Song et al., 2021) new
- the HUIM-HC algorithm (Fournier-Viger et al., 2021) new
- the HUIM-SA algorithm (Fournier-Viger et al., 2021) new
- the HUIM-ACO algorithm (Song et al., 2020) new
- the HUIM-SPSO algorithm (Song et al., 2020) new
- the HUIF-PSO algorithm (Song et al., 2018)
- the HUIF-GA algorithm (Song et al., 2018)
- the HUIF-BA algorithm (Song et al., 2018)
- the HUIM-ABC algorithm (Song et al., 2018)
- the HUIM-GA algorithm (Kannimuthu et al., 2014)
- the HUIM-BPSO algorithm (Lin et al., 2016)
- the HUIM-GA-tree algorithm (Lin et al., 2016)
- the HUIM-BPSO-tree algorithm (Lin et al., 2016)
- algorithm for mining high average-utility itemsets
- the HAUI-Miner (Lin et al., 2016)
- the EHAUPM (Lin et al., 2017)
- the HAUIM-GMU (Song et al., 2021) new
- the HAUI-MMAU – with multiple thresholds (Lin et al., 2016)
- the MEMU – with multiple thresholds (Lin et al., 2018)
- algorithms for mining the top-k high average-utility itemsets
- the ETAUIM algorithm (2023) new - obtained under the GPL license from Github liuxuan615
- algorithms for mining high-utility episodes
in a sequence of complex events containing utility information
- the HUE-SPAN algorithm (Fournier-Viger et al., 2019, 📊 slides) new
- the TUP algorithm (Rathore et al., 2016)
- the UP-SPAN algorithm (Wu et al., 2013)
- algorithms for mining periodic high-utility patterns
- the PHM algorithm (Fournier-Viger et al., 2016, 📊 slides)
- the PHMN and PHMN+ algorithms (2023) - obtained from Github @laughing1999 under the GPL license)
- algorithms for discovering irregular high-utility itemsets
- the PHM_irregular algorithm (variation of PHM) new
- algorithm for discovering local high-utility itemsets
- the LHUI-Miner (Fournier-Viger et al., 2019, 📊 slides) new
- algorithm for discovering peak high-utility itemsets
- the PHUI-Miner (Fournier-Viger et al., 2019, 📊 slides) new
- algorithm for discovering locally trending high-utility itemsets
- the LTHUI-Miner (Fournier-Viger et al., 2020, ▶ video 📊 slides) new
- algorithm for high-utility itemset mining with a recency constraint
- the ScentedUtilityMiner algorithm (Sra et al., 2024) new
- algorithm for discovering high-utility association rules
- the HGB_all algorithm – all or non-redundant high-utility association rules (Sahoo et al., 2015) new
- the HGB algorithm – non-redundant high-utility association rules (Sahoo et al., 2015) new
Association Rule Mining
These algorithms discover interesting associations between symbols (values) in a transaction database (database records with binary attributes).
- an algorithm for mining all association rules with the confidence measure (Agrawal & Srikant, 1994, ▶ video)
- an algorithm for mining all association rules with the lift measure (adapted from Agrawal & Srikant, 1994)
- an algorithm for mining the IGB informative and generic basis of association rules (Gasmi et al., 2005)
- an algorithm for mining perfectly sporadic association rules (Koh & Roundtree, 2005)
- an algorithm for mining closed association rules (Szathmary et al., 2006)
- an algorithm for mining minimal non-redundant association rules (Kryszkiewicz, 1998)
- the Indirect algorithm – indirect association rules (Tan et al., 2000; Tan et al., 2006)
- the FHSAR algorithm – hiding sensitive association rules (Weng et al., 2008)
- the TopKRules algorithm – top-k association rules (Fournier-Viger, 2012, 📊 slides)
- the ETARM algorithm – top-k association rules (Nguyen et al., 2017) new
- the FTARM algorithm – top-k association rules (Liu et al., 2019) new
- the TopKClassRules algorithm – top-k class association rules (Fournier-Viger, 2012, 📊 slides)
- the TNR algorithm – top-k non-redundant association rules (Fournier-Viger, 2012, 📊 slides)
- the HGB and HGB_All – high-utility association rules (Sahoo et al., 2015) new
- algorithms for mining class association rules
- the ACAC algorithm (Huang et al., 2011)
- the ACCF algorithm (Li et al., 2008)
- the ACN algorithm (Kundu et al., 2008)
- the ADT algorithm (Wang et al., 2000)
- the CBA algorithm (Liu et al., 1998)
- the CBA2 algorithm (Liu et al., 2001)
- the CMAR algorithm (Li et al., 2001)
- the L3 algorithm (Baralis et al., 2002)
- the MAC algorithm (Abdelhamid et al., 2012)
Stream Pattern Mining
These algorithms discover various kinds of patterns in a stream (an infinite sequence of database records).
- the estDec algorithm – recent frequent itemsets in a data stream (Chang & Lee, 2003)
- the estDec+ algorithm – recent frequent itemsets in a data stream (Shin et al., 2014)
- the CloStream algorithm – frequent closed itemsets in a data stream (Yen et al., 2009)
- algorithms for mining the top-k high-utility itemsets from a data stream
- the FHMDS and FHMDS-Naive algorithms (Dawar et al., 2017)
Clustering
These algorithms automatically find clusters in different kinds of data.
- the original K-Means algorithm (MacQueen, 1967)
- the Bisecting K-Means algorithm (Steinbach et al., 2000)
- the K-Means++ algorithm (Arthur et al., 2007) new
- algorithms for density-based clustering
- the DBScan algorithm (Ester et al., 1996)
- the Optics algorithm - extract a cluster ordering of points, which can then be use to generate DBScan style clusters and more (Ankerst et al., 1999)
- the Density Peak Clustering (DPC) algorithm (Rodriguez et al., 2014)
- the AEDBScan algorithm (Mistry et al., 2021)
- a hierarchical clustering algorithm
- a tool called Cluster Viewer for visualizing clusters
- a tool called Instance Viewer for visualizing the input of clustering algorithms
Time Series Mining
These algorithms perform various tasks to analyze time series data.
- converting a time series to a sequence of symbols using the SAX representation of time series. Note that if one converts a set of time series with SAX, he will obtain a sequence database, which allows to then apply traditional algorihtms for sequential rule mining and sequential pattern mining on time series (SAX, 2007)
- calculating the prior moving average (noise removal) of a time series
- calculating the cumulative moving average (noise removal) of a time series
- calculating the central moving average (noise removal) of a time series
- calculating the median smoothing (noise removal) of a time series
- calculating the exponential smoothing (noise removal) of a time series
- calculating the min-max normalization of a time series
- calculating the autocorrelation function of a time series
- calculating the standardization of a time series
- calculating the first and second order differencing of a time series
- calculating the piecewise aggregate approximation (data point reduction) of a time series
- calculating the linear regression (least squares method) of a time series
- splitting a time series into segments of a given length
- splitting a time series into a given number of segments
- clustering time series(group time-series according to their similarities). This can be done by applying the clustering algorithms offered in SPMF (K-Means, Bisecting K-Means, DBScan, OPTICS, Hierarchical clustering) on time series.
- a tool called Time Series Viewer for visualizing time series
Classification
- the ID3 algorithm for building decision trees (Quinlan, 1986)
- the KNN (K-Nearest Neighbor) algorithm
- classification based on class association rule mining
- the ACAC algorithm (Huang et al., 2011)
- the ACCF algorithm (Li et al., 2008)
- the ACN algorithm (Kundu et al., 2008)
- the ADT algorithm (Wang et al., 2000)
- the CBA algorithm (Liu et al., 1998)
- the CBA2 algorithm (Liu et al., 2001)
- the CMAR algorithm (Li et al., 2001)
- the L3 algorithm (Baralis et al., 2002)
- the MAC algorithm (Abdelhamid et al., 2012)
- a framework for comparing multiple classifiers using holdout and k-fold cross-validation
Text Mining
- an algorithm for classifying text documents using a Naive Bayes classifier approach (S. Raghu, 2015)
- an algorithm for clustering texts using the tf*idf measure (S. Raghu, 2015)
Dataset Generation Tools
- A tool for generating a synthetic transaction database
- A tool for generating a synthetic sequence database
- A tool for generating a synthetic sequence database with timestamps
- A tool for generating datasets for clustering
Dataset Transformation Tools
- A tool for converting a sequence database to a transaction database
- A tool for converting a transaction database to a sequence database
- A tool for converting a text file to a sequence database (each sentence becomes a sequence)
- A tool for converting a sequence database in various formats (CSV, KOSARAK, BMS, IBM…) to SPMF format
- A tool for converting a transaction database in various formats (CSV…) to SPMF format
- A tool for converting time-series to a sequence database
- A tool to generate utility values for a transaction database
- A tool to add timestamps to a sequence database
- A tool to fix a transaction database having problems (with or without utility/time information)
- A tool for removing utility information from a database having utility information
- A tool to resize a database in SPMF format using a percentage of lines
- A tool to sample records from a dataset (reservoir, seed, etc.)
- A tool to remove duplicated records from a dataset
Dataset Statistics Tools
- A tool for calculating statistics about a transaction database
- A tool for calculating statistics about a transaction database with utility information
- A tool for calculating statistics about a sequence database
- A tool for calculating statistics about a graph database
- A tool for calculating statistics about a product transaction database new
- A tool for calculating statistics about a sequence database with cost and binary utility new
- A tool for calculating statistics about a sequence database with cost and numeric utility new
- A tool for calculating statistics about a sequence database with utility new
- A tool for calculating statistics about a time-extended sequence database new
- A tool for calculating statistics about a transaction database with cost and utility new
- A tool for calculating statistics about a transaction database with utility and period information new
- A tool for calculating statistics about a transaction database with utility and timestamps new
- A tool for calculating statistics about an event sequence new
- A tool for calculating statistics about an interval sequence database new
- A tool for calculating statistics about a multi-dimensional sequence database new
- A tool for calculating statistics about a multi-dimensional sequence database with timestamps new
- A tool for calculating statistics about an uncertain transaction database new
- A tool for calculating statistics about a file with double vectors (instances) for clustering
- A tool for calculating statistics about time series
Dataset Viewer Tools
- A time series viewer to visualize time series
- A cluster viewer to visualize clusters produced by clustering algorithms
- A graph viewer to view files containing graphs or subgraphs (TKG, gSpan, cgSpan)
- A simple tool to view the content of an ARFF file new
- A tool to view the content of an event sequence file new
- A tool to view a sequence database cost binary utility file new
- A tool to view a sequence database cost numeric utility file new
- A tool to view a sequence database file new
- A tool to view a time-extended sequence database new
- A tool to view a multi-dimensional sequence database new
- A tool to view a multi-dimensional time sequence database new
- A tool to view a sequence utility database file new
- A tool to view a cost utility transaction database file new
- A tool to view a transaction database file new
- A tool to view an uncertain transaction database file new
- A tool to view a utility transaction database file new
- A tool to view a utility time transaction database file new
- A tool to view a utility period transaction database file new
- A tool to view a product transaction database file new
- A tool to view a graph database file
- A tool to view a sequence database file with time intervals new
- A tool to view a taxonomy file new
GUI Tools
- The Algorithm Explorer tool to explore the algorithms offered in SPMF
- The Memory Viewer tool to observe the memory usage of algorithms in real-time new
- The Pattern Viewer tool to view patterns found by algorithms and their frequency distributions
- The Workflow Editor tool to create a workflow with several algorithms and run it new
- A tool to run experiments where one or more algorithms are run and a parameter is varied
- The SPMF text editor
- A tool to download an offline copy of the SPMF documentation new
- A tool called Pattern Diff Analyzer to compare two files of patterns to find contrast patterns new
- A tool called Algorithm Graph Viewer to view the similarity between algorithms as a graph new
Other Tools
- A tool to export the list of algorithms to a JSON file new
Data Structures
- Red-black tree
- Itemset-tree
- Binary tree
- KD-tree
- Triangular matrix
- A collection of optimized primitive-type data structures to replace hashmaps, lists, sets, etc.
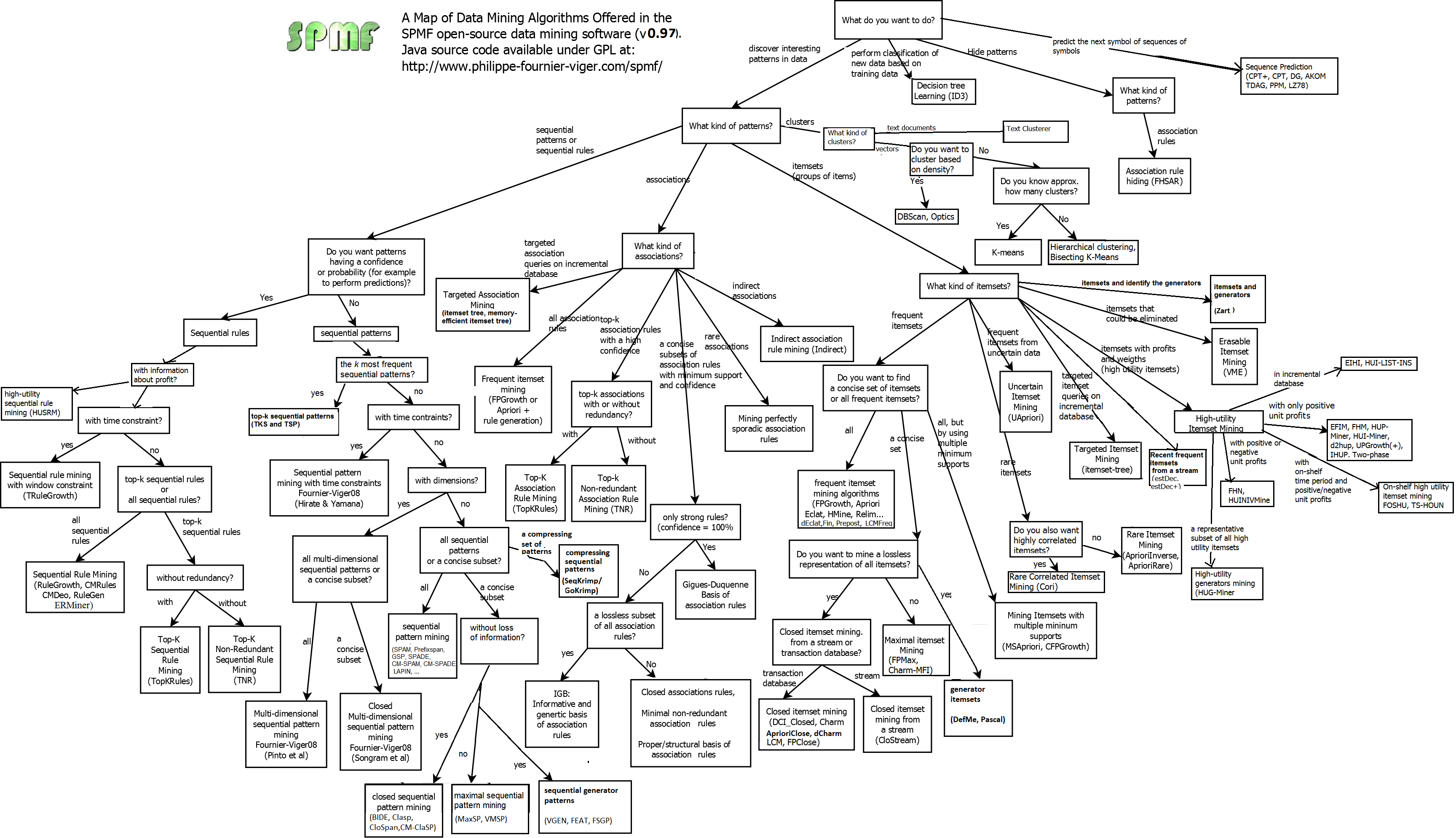
Visual Map of Algorithms
You can visualize the relationship between the various data mining algorithms offered in SPMF by clicking on this map (last updated: 2015/09/12 – SPMF 0.97):